我们把 WebStreams“Ralph Wiggum 化”,性能提升最高 14.6 倍

9 分钟阅读
2026 年 2 月 18 日
今年早些时候,我们开始对 Next.js 服务端渲染做性能剖析时,有一个东西在火焰图里反复出现:WebStreams。不是流里跑的应用代码,而是流本身。Promise 链、每个 chunk 的对象分配、微任务队列跳转。在 Theo Browne 的服务端渲染基准测试指出框架开销占用了大量计算时间之后,我们开始追踪这些时间到底花在了哪里。很大一部分都在 streams 上。
结果发现,WebStreams 有一套极其完整的测试集,这让它非常适合用 AI 做“基于测试驱动 + 基准驱动”的重实现。本文会讲我们做了哪些性能优化、踩了哪些坑,以及这些工作如何已经通过 Matteo Collina 的上游 PR进入 Node.js 本体。
Link to heading问题所在
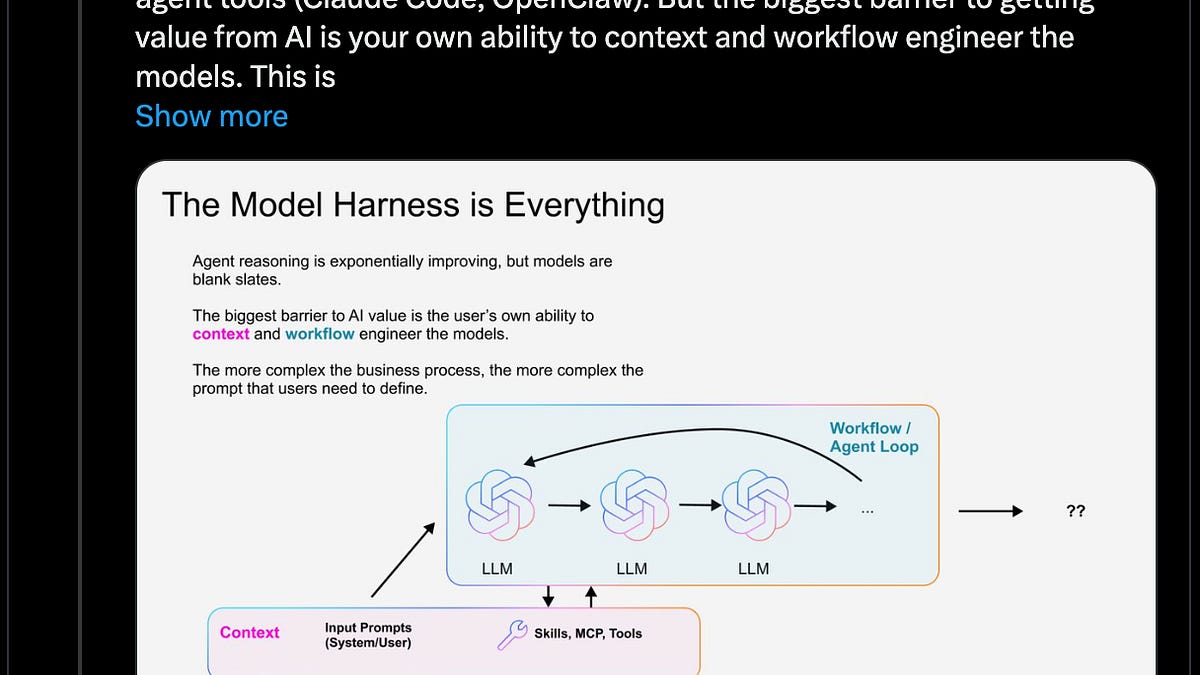
Node.js 有两套流 API。老一代(stream.Readable、stream.Writable、stream.Transform)已经存在十多年,优化非常充分。数据走的是 C++ 内部路径,背压是一个布尔值,管道连接就是一次函数调用。
新一代是 WHATWG Streams API:ReadableStream、WritableStream、TransformStream。这是 Web 标准,支撑了 fetch() 响应体、CompressionStream、TextDecoderStream,以及越来越多框架(如 Next.js、React)的服务端渲染。
向 Web 标准收敛是正确方向。但在服务端,它比应有的速度更慢。
要理解原因,可以看在 Node.js 里调用原生 WebStream 的 reader.read() 时发生了什么。即使数据已经在缓冲区里:
- 会分配一个带 3 个回调槽位的
ReadableStreamDefaultReadRequest对象 - 这个 request 会被入队到流的内部队列
- 新建并返回一个 Promise
- 最终解析还要走一遍微任务队列
也就是说,为了返回“本来就在那里”的数据,要付出 4 次分配 + 1 次微任务跳转。再把这个成本乘以渲染流水线里每个 transform 上流经的每个 chunk。
再看 pipeTo():每个 chunk 都会经过完整 Promise 链:read、write、检查背压、再来一轮。每次 read 还会分配一个 {value, done} 结果对象。错误传播会再产生额外的 Promise 分支。
这些设计本身并没错。在浏览器里这些保证很重要:流跨越安全边界、取消语义必须严密、pipe 两端并不在你控制范围内。但在服务端,如果你在 1KB chunk 粒度下,把 React Server Components 通过 3 层 transform 管道传输,成本就会迅速累积。
我们测得原生 WebStream pipeThrough 在 1KB chunk 下吞吐是 630 MB/s。同样的 passthrough transform,用 Node.js pipeline() 可以到 ~7,900 MB/s。差了 12 倍,而且几乎全是 Promise 和对象分配带来的开销。
Link to heading我们做了什么
我们一直在做一个叫 fast-webstreams 的库:对外实现 WHATWG 的 ReadableStream、WritableStream、TransformStream API,内部则用 Node.js streams 做承载。API 一样、错误传播一样、规范兼容性一样,但把常见路径上的额外开销去掉了。
核心思路是:根据实际操作类型,走不同的快路径。
Link to heading快流之间 pipe:每个 chunk 零 Promise
这是最大的收益点。当你在 fast streams 之间链式调用 pipeThrough / pipeTo 时,库不会立刻开始传输,而是先记录上游链路:
source → transform1 → transform2 → ...
当链尾调用 pipeTo() 时,它会向上回溯,收集底层 Node.js stream 对象,然后只发起一次 pipeline()。一次函数调用,每个 chunk 零 Promise,数据直接走 Node 已优化的 C++ 路径。
const source = new ReadableStream({ pull(controller) { controller.enqueue(generateChunk()); }});const transform = new TransformStream({ transform(chunk, controller) { controller.enqueue(process(chunk)); }});const sink = new WritableStream({ write(chunk) { consume(chunk); }});// Internally: single pipeline() call, zero promises per chunk
await source.pipeThrough(transform).pipeTo(sink);
结果:~6,200 MB/s。比原生 WebStreams 快约 10 倍,并且接近原始 Node.js pipeline 性能。
如果链中有任意一个流不是 fast stream(例如原生 CompressionStream),库会回退到原生 pipeThrough 或规范兼容的 pipeTo 实现。
Link to heading逐 chunk 读取:同步解析
调用 reader.read() 时,库会先同步尝试 nodeReadable.read()。有数据就直接 Promise.resolve({value, done});不走事件循环往返,不分配 request 对象。只有缓冲区为空时,才注册 listener 并返回 pending Promise。
const reader = stream.getReader();while (true) { const { value, done } = await reader.read(); if (done) break; // When data is buffered, the await resolves immediately // via Promise.resolve() — no microtask queue hop processChunk(value);}
结果:~12,400 MB/s,约是原生的 3.7 倍。
Link to headingReact Flight 模式:差距最大的场景
这对 Next.js 最关键。React Server Components 使用的是一种特定字节流模式:创建 type: 'bytes' 的 ReadableStream,在 start() 里拿到 controller,然后随着渲染推进从外部 enqueue。
let ctrl;const stream = new ReadableStream({ type: 'bytes', start(c) { ctrl = c; }});// As React renders each component:
ctrl.enqueue(new Uint8Array(payload1));ctrl.enqueue(new Uint8Array(payload2));ctrl.close();
原生 WebStreams:~110 MB/s。fast-webstreams:~1,600 MB/s。也就是 14.6 倍,而且正是生产环境服务端渲染在用的模式。
提速来自我们写的 LiteReadable:一个最小化的数组缓冲实现,用来替代 Node.js Readable 处理字节流。它用直接回调分发代替 EventEmitter,支持 pull-based demand 和 BYOB reader,单次构造成本还能再低约 5 微秒。React Flight 每个请求会创建数百个字节流,这点优化就很关键。
Link to headingfetch 响应体:你无法自行构造的流
上面的例子都从 new ReadableStream(...) 开始。但在服务端,大多数流其实来自 fetch()。响应体是 Node.js HTTP 层持有的原生字节流,你不能直接替换。
这是 SSR 很常见的路径:从上游服务拉数据,通过一个或多个 transform,再转发给客户端。
const upstream = await fetch('<https://api.example.com/data>');// Pipe through transforms and forward as a new Response
const transformed = upstream.body .pipeThrough(new TransformStream({ transform(chunk, ctrl) { /* ... */ ctrl.enqueue(chunk); } })) .pipeThrough(new TransformStream({ transform(chunk, ctrl) { /* ... */ ctrl.enqueue(chunk); } })) .pipeThrough(new TransformStream({ transform(chunk, ctrl) { /* ... */ ctrl.enqueue(chunk); } }));return new Response(transformed);
原生 WebStreams 下,链路每一跳都要付出每 chunk Promise 的全套成本。3 个 transform 大致就是每 chunk 6~9 个 Promise。1KB chunk 时吞吐约 ~260 MB/s。
这个库通过“延迟解析”处理该问题:启用 patchGlobalWebStreams() 后,Response.prototype.body 返回的是包裹原生字节流的轻量 fast shell。调用 pipeThrough() 不会立刻开始传输,只记录链路;直到链尾调用 pipeTo() 或 getReader(),才一次性解析整条链:在原生 reader 到 Node.js pipeline() 之间建立单桥接,再从输出缓冲同步读取。
成本模型是:原生边界拉数据时 1 个 Promise;transform 链内部每 chunk 0 Promise;输出端同步 read。
结果:3-transform 的 fetch 模式达到 ~830 MB/s,比原生快 3.2 倍。若只是简单响应转发(无 transform),也有 2.0 倍(850 vs 430 MB/s)。
Link to heading基准测试
所有数据均为 Node.js v22、1KB chunk 下的吞吐(MB/s),数值越高越好。
Link to heading核心操作
Operation
Node.js streams
fast
native
fast vs native
read loop
26,400
12,400
3,300
3.7x
write loop
26,500
5,500
2,300
2.4x
pipeThrough
7,900
6,200
630
9.8x
pipeTo
14,000
2,500
1,400
1.8x
for-await-of
—
4,100
3,000
1.4x
Link to headingTransform 链
每 chunk Promise 开销会随着链深叠加:
Depth
fast
native
fast vs native
3 transforms
2,900
300
9.7x
8 transforms
1,000
115
8.7x
Link to heading字节流
Pattern
fast
native
fast vs native
start + enqueue (React Flight)
1,600
110
14.6x
byte read loop
1,400
1,400
1.0x
byte tee
1,200
750
1.6x
Link to heading响应体模式
Pattern
fast
native
fast vs native
Response.text()
900
910
1.0x
Response forwarding
850
430
2.0x
fetch → 3 transforms
830
260
3.2x
Link to heading流构造
流创建速度也更快,这对短生命周期流很重要:
Type
fast
native
fast vs native
ReadableStream
2,100
980
2.1x
WritableStream
1,300
440
3.0x
TransformStream
470
220
2.1x
Link to heading规范兼容性
fast-webstreams 通过了 1,116 项 Web Platform Tests 中的 1,100 项。Node.js 原生实现通过 1,099 项。剩余 16 项失败要么是原生同样存在的问题(例如尚未实现的 type: 'owning' 传输模式),要么是不会影响真实应用的架构差异。
Link to heading我们如何落地部署
该库可直接 patch 全局 ReadableStream、WritableStream、TransformStream 构造器:
import { patchGlobalWebStreams } from 'fast-webstreams';
patchGlobalWebStreams();// globalThis.ReadableStream is now the fast implementation// fetch() response bodies are automatically wrapped// All downstream pipeThrough/pipeTo use fast paths
这个 patch 还会拦截 Response.prototype.body,把原生 fetch 响应体包裹成 fast stream shell,让 fetch() → pipeThrough() → pipeTo() 链路自动命中 pipeline 快路径。
在 Vercel,我们正在评估将其逐步推广到整个集群。推进会谨慎且渐进。流原语位于请求处理、响应渲染、压缩等基础路径。我们会先覆盖差距最大的模式:React Server Component 流式传输、响应体转发、多级 transform 链,并先在生产环境观测,再扩大范围。
Link to heading正确的修复方向是上游
长期来看,用户态库不该是最终答案。真正的修复应在 Node.js 本身。
相关工作已经开始。我们在 X 上交流后,Matteo Collina 提交了 nodejs/node#61807:“stream: add fast paths for webstreams read and pipeTo”。这个 PR 将本项目的两个思路直接应用到 Node.js 原生 WebStreams:
read()快路径:当数据已在缓冲区时,直接返回 resolved Promise,不再创建ReadableStreamDefaultReadRequest对象。这依旧符合规范,因为read()无论如何都返回 Promise,而 resolved Promise 的回调仍在微任务队列执行。pipeTo()批量读取:当数据已缓冲时,从 controller 队列批量读取,避免每个 chunk 分配 request 对象;每次 write 后检查desiredSize,确保背压语义不被破坏。
PR 显示:缓冲读取快 ~17–20%,pipeTo 快 ~11%。这些改进将让所有 Node.js 用户“零成本”受益:无需安装库、无需 patch、风险更低。
James Snell 的 Node.js performance issue #134 还列出了更多机会:内部来源流走 C++ 级别 piping、lazy buffering、消除 WritableStream 适配器中的双缓冲。每一项都可能进一步缩小差距。
我们会继续向上游贡献思路。目标不是让 fast-webstreams 永远存在,而是让 WebStreams 快到不再需要它。
Link to heading我们踩坑后得到的经验
规范比看上去更“聪明”。 我们尝试过很多捷径,几乎每一条都会打破某个 WPT,而测试通常是对的。ReadableStreamDefaultReadRequest 模式、每次读取都返回 Promise 的设计、严密的错误传播机制——这些都不是偶然,它们是为了解决真实边界情况:读取中取消、锁定流中的错误标识一致性、thenable 拦截等,真实代码确实会触发。
Promise.resolve(obj) 总会检查 thenable。 这是语言级行为,绕不开。如果 resolve 的对象带 .then 属性,Promise 机制就会调用它。有些 WPT 会故意给 read 结果挂 .then 并验证实现是否正确处理。我们因此必须非常谨慎地决定 {value, done} 在热路径中的创建位置。
Node.js 的 pipeline() 不能直接替代 WHATWG 的 pipeTo。 我们原本希望所有 pipe 都统一走 pipeline(),结果导致 72 项 WPT 失败。错误传播、流锁定、取消语义在两者之间本质不同。只有在我们完全控制整条链时 pipeline() 才安全,这也是我们“先收集上游链接、仅对纯 fast-stream 链使用它”的原因。
要用 Reflect.apply,不要用 .call()。 WPT 会 monkey-patch Function.prototype.call,并验证实现不会用它调用用户回调。安全做法只有 Reflect.apply。这是实打实的规范要求。
Link to heading我们用 AI 完成了 fast-webstreams 的大部分实现
有两件事让这成为可能:
The amazing [W
[... 内容截断 ...]
原文链接:https://vercel.com/blog/we-ralph-wiggumed-webstreams-to-make-them-10x-faster