执行框架工程真有价值吗?
深度Latent Space2026年3月5日6 分钟阅读
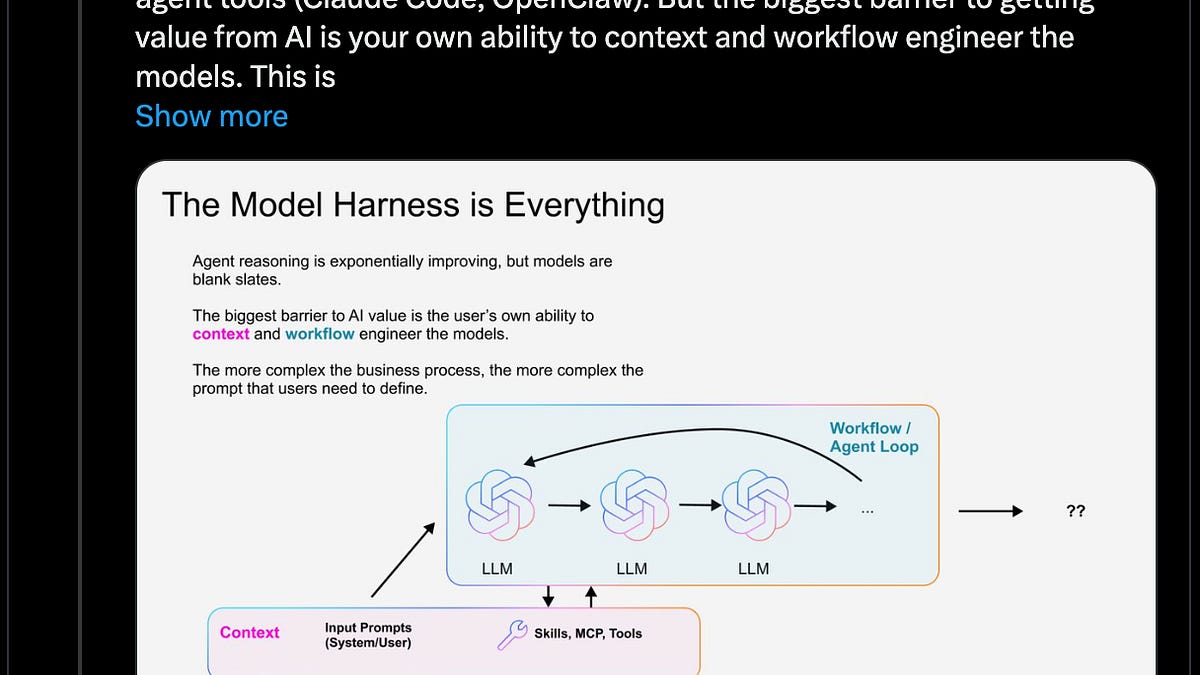
AI 工程界正激烈争论:智能体的核心价值究竟来自大模型本身,还是包裹它的执行框架(Harness)?Claude Code 团队认为框架越薄越好,而另一些团队则用数据证明优化框架能显著提升所有模型表现。
本文编译自 [AINews] Is Harness Engineering real?,版权归原作者所有。
觉得有用?分享给更多人
觉得有用?分享给更多人
Black Forest Labs 推出 FLUX 3,统一多模态模型,视频生成超越多个竞品,并开源 FLUX-mimic 用于机器人控制。同时,The Stack v3 数据集发布,蒸馏政策争议持续。
本文采访了多位进攻型网络安全研究员,探讨AI公司的安全护栏如何影响他们发现漏洞和开发利用工具的工作。研究员们普遍认为护栏过于严格且不一致,迫使部分人转向国产开源模型。