“bash 足够了吗?”实测:SQL Agent 碾压,混合方案达成 100% 准确率

5 分钟阅读
2026 年 1 月 22 日
我们邀请了来自 Ankur Goyal 和 Braintrust 的团队,分享他们如何验证“bash is all you need”这一 AI Agent 假设。
AI 社区里有一种越来越强的观点:对 AI Agent 来说,文件系统和 bash 是最优抽象。这套逻辑看起来很合理:LLM 在代码、终端和文件导航上受过大量训练,因此给 Agent 一个 shell,它就应该能把任务完成。
即便是非编码类 Agent,也可能从这种方式中受益。Vercel 最近关于用文件系统和 bash 构建 Agent的文章就展示了这一点:把销售通话、客服工单等结构化数据映射到文件系统中,Agent 通过 grep 找到相关片段,提取所需信息,并按需构建上下文。
但还有另一种值得验证的观点:文件系统也许适合做探索和上下文检索,但在结构化数据查询上呢?我们构建了一个 eval harness来验证这个问题。
Link to heading搭建评测
我们给 Agent 的任务是查询一个包含 GitHub issues 和 pull requests 的数据集。这类半结构化数据与真实场景高度相似,例如客服工单或销售通话转录。
问题复杂度覆盖:
-
简单查询:“有多少 open issue 提到了 ‘security’?”
-
复杂查询:“找出有人报告 bug,随后又有人提交声称修复该 bug 的 pull request 的 issue”
共有三种 Agent 方案参赛:
-
SQL Agent:直接查询同一份数据构建的 SQLite 数据库
-
Bash Agent:使用
just-bash在文件系统中导航并查询 JSON 文件 -
Filesystem Agent:只用基础文件工具(search、read),不提供完整 shell 权限
每个 Agent 都接收同样的问题,并按准确率评分。
Link to heading初始结果
Agent
Accuracy
Avg Tokens
Cost
Duration
SQL
100%
155,531
$0.51
45s
Bash
52.7%
1,062,031
$3.34
401s
Filesystem
63.0%
1,275,871
$3.89
126s
SQL 明显领先:准确率 100%,而 bash 只有 53%。bash 的 Token 消耗高 7 倍、成本高 6.5 倍、耗时高 9 倍。甚至仅使用基础文件系统工具(search、read)也优于完整 bash,达到 63% 准确率。
你可以直接查看SQL 实验、bash 实验和filesystem 实验结果。
一个出人意料的发现是,bash Agent 生成了非常复杂的 shell 命令:以很少见于常规 Agent 工作流的方式,把 find、grep、jq、awk、xargs 串联起来。模型显然具备很深的 shell 脚本知识,但这种知识并没有转化为更好的任务表现。
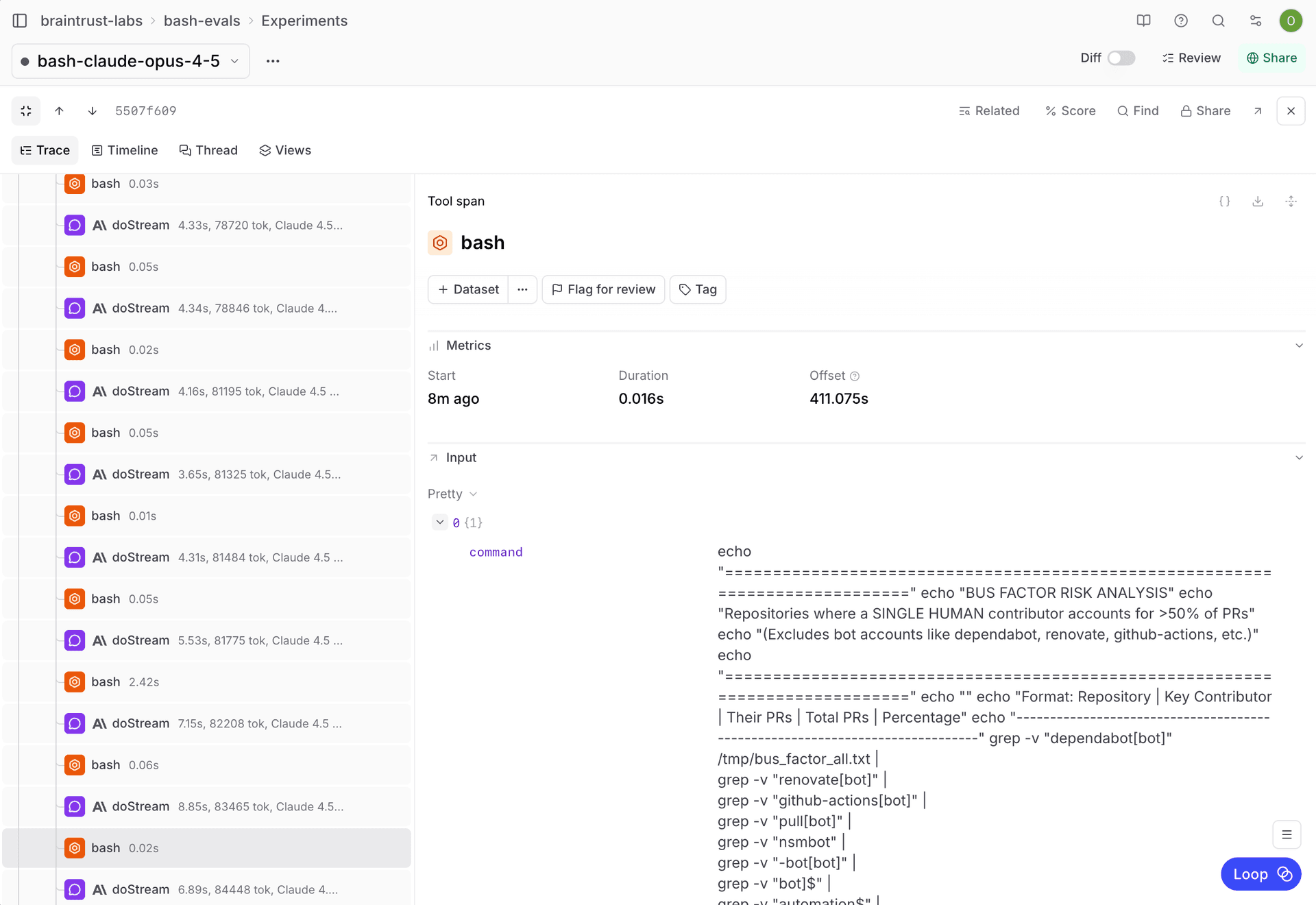
复杂的 shell 脚本并未转化为准确率提升
Link to heading调试结果
评测暴露出一些需要重点处理的实质性问题。
性能瓶颈。 本应毫秒级完成的命令,在 10 秒时超时。罪魁祸首是对 68,000 个文件进行 stat() 调用。随后just-bash 工具进行了优化来解决该问题。
缺少 schema 上下文。 bash Agent 不知道它要查询的 JSON 文件结构。我们在 system prompt 里加入 schema 信息和示例命令后有所改善,但仍不足以弥合差距。
评测打分问题。 对失败样本做人工复核后发现,多个问题里的“预期答案”本身有误,或 Agent 找到了额外有效结果却被评分器扣分。有 5 个问题因歧义或数据集不匹配被修正。
-
“哪些仓库拥有最多的独立 issue 报告者”在组织级分组和仓库级分组之间存在歧义
-
若干问题的预期输出与实际数据集不一致
-
bash Agent 有时能找到比参考答案更多的有效结果
Vercel 团队提交了包含这些修正的PR。
在 just-bash 和评测本身都修复后,性能差距显著缩小。
Link to heading混合方案
随后我们尝试了另一种思路:不再二选一,而是两者都给 Agent:
-
允许它用 bash 探索和操作文件
-
同时在合适场景下提供 SQLite 数据库访问
混合 Agent 形成了一种有趣行为:先跑 SQL 查询,再通过在文件系统里 grep 来验证结果。正是这种双重校验,让混合方案稳定达到 100% 准确率,而纯 SQL 偶尔仍会出错。
你可以直接查看混合实验结果。
代价是成本:由于需要判断工具选择并执行结果校验,混合方案的 Token 消耗大约是纯 SQL 的两倍。
Link to heading关键结论
在修复 just-bash、评测数据集以及数据加载问题后,bash-sqlite 成为最可靠的方案。最终“赢家”并不是单次运行里的最高准确率,而是通过自校验获得的一致性准确率。
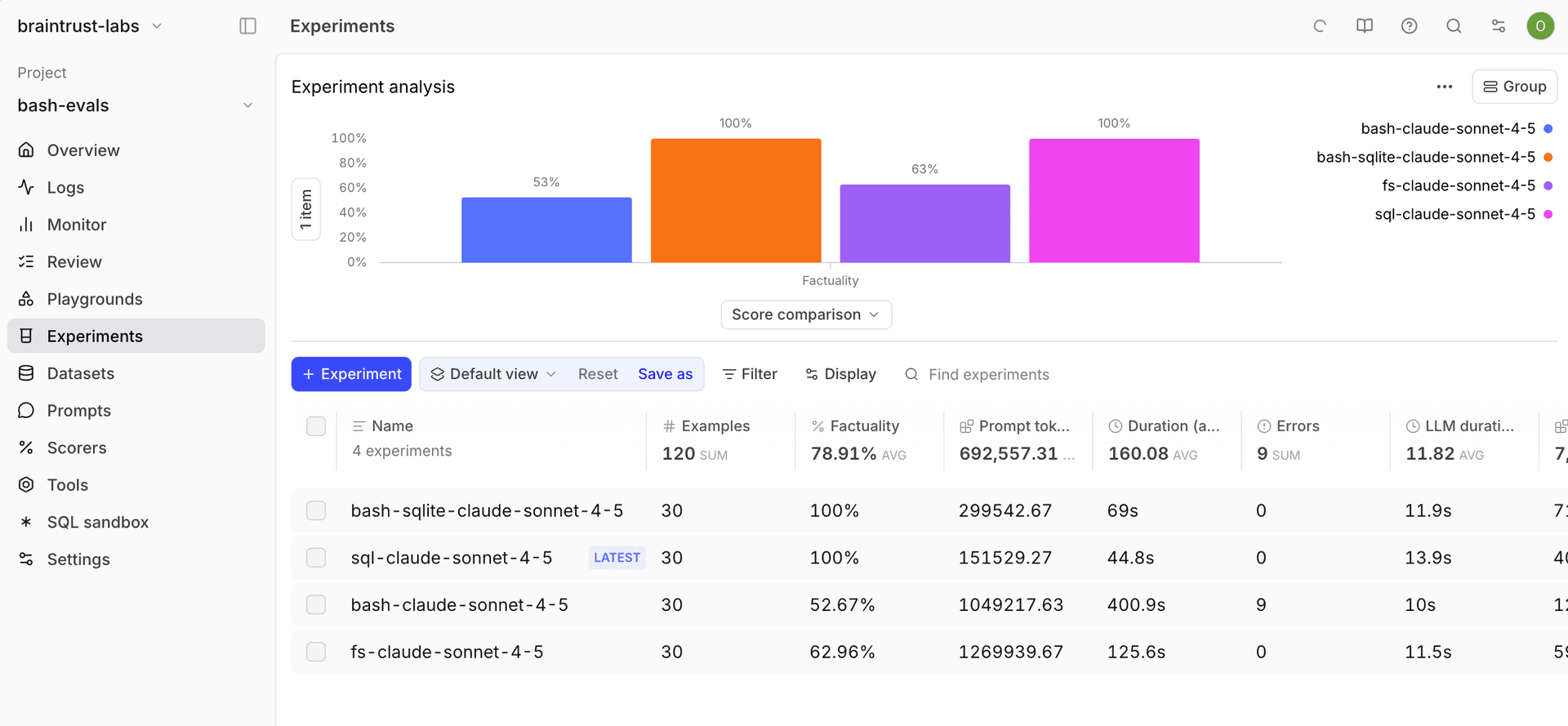
混合方案在准确率上追平 SQL,同时增加自校验能力
在 200 多条消息和数百条 trace 之后,我们完成了:
-
修复
just-bash的性能瓶颈 -
修正评测中 5 个含糊或错误的预期答案
-
发现一个导致 off-by-one 错误的数据加载 bug
-
观察到 Agent 形成更复杂的校验策略
bash Agent 倾向于自检这一特性被证明很有价值——它不仅影响准确率,更能暴露纯 SQL 路径下可能被忽略的问题。
Link to heading这对 Agent 设计意味着什么
对于 schema 清晰的结构化数据,SQL 仍是最直接路径:快、成熟、Token 消耗低。
对于探索和验证,bash 提供了 SQL 难以替代的灵活性。Agent 可以检查文件、抽样核对结果,并通过文件系统访问捕捉边缘情况。
但更大的启示其实在 eval 本身。Braintrust 与 Vercel 团队基于每一步详细 trace 的反复协作,才真正推动了工具和基准改进。没有这种可观测性,我们可能仍在基于有缺陷的数据争论哪种抽象“胜出”。
Link to heading运行你自己的基准测试
你可以替换自己的:
-
数据集(客服工单、销售通话、日志,或任何你的业务数据)
-
Agent 实现
-
与业务场景相关的问题集
本文由 Ankur Goyal 与 Braintrust 团队撰写。Braintrust 专注于 AI 应用评测基础设施。该 eval harness 已开源,并可集成 Vercel 的 _just-bash_。
原文链接:https://vercel.com/blog/testing-if-bash-is-all-you-need