LLM 可大规模“揭面”化名用户,准确率高得出人意料

“我们的发现是,这些 AI Agent 能做到一件过去非常困难的事:从自由文本(比如匿名化的访谈记录)出发,一步步还原出一个人的完整身份。”论文联合作者 Simon Lermen 在接受 Ars 采访时表示,“这是一项相当新的能力;此前的重识别方法通常需要结构化数据,以及两份能按相似 schema 进行关联的数据集。”
Lermen 说,与那些较早的“去化名”方法不同,AI Agent 可以浏览网页,并以许多与人类相同的方式与网络交互。它们还可以通过模拟推理去匹配潜在个体。在一项实验中,研究人员使用了 Anthropic 就“不同人如何在日常生活中使用 AI”所做问卷的回答。基于这些答案中的信息,研究人员成功识别出 125 名参与者中的 7%。
![Column 1: Q: How did you use Al tools in a recent research project? A: I work in biology, on research related to [research topic]. My supervisor and I recently talked about analysing the impact [of specific phenomenon]... My background is in physical science... A: I used Al tools frequently... for writing [specific library] code 2nd collum Profile: • Computational biology, [subfield] • Education: physical science background • Likely PhD student or postdoc • Tools: Python, [specific library] • British English ("analysing") → UK or Commonwealth Third collumn: PhD Student in Biology, [University], UK • Research subfield 8[bioRxiv preprint] • [Research methodology] • PhD student @[University profile] v UK-based • Using [specific library] in • [GitHub repo]](https://cdn.arstechnica.net/wp-content/uploads/2026/03/results-from-questionaire.jpg)
从单份访谈记录实现端到端去匿名化(细节已修改以保护受试者身份)。一个 LLM Agent 从对话中提取结构化身份信号,随后自主进行网络搜索锁定候选人,并验证该候选人与所有提取出的主张一致。
从单份访谈记录实现端到端去匿名化(细节已修改以保护受试者身份)。一个 LLM Agent 从对话中提取结构化身份信号,随后自主进行网络搜索锁定候选人,并验证该候选人与所有提取出的主张一致。
尽管 7% 的召回率相对不高,但这证明了 AI 正在具备基于用户提供的高度泛化信息来识别个人的能力。Lermen 表示:“AI 能做到这件事本身就很值得关注。随着 AI 系统不断进步,它们很可能会越来越擅长找出更多人的身份。”
在第二项实验中,研究人员收集了 2024 年 r/movies 子版块,以及以下五个较小社区中至少一个社区的评论:r/horror、r/MovieSuggestions、r/Letterboxd、r/TrueFilm 和 r/MovieDetails。结果显示,候选人讨论过的电影越多,就越容易被识别。对于只共享 1 部电影的用户,平均有 3.1% 可在 90% precision 下被识别,1.2% 可在 99% precision 下被识别。当共享电影数达到 5 到 9 部时,90% 和 99% precision 下的识别比例分别上升到 8.4% 和 2.5%。共享电影超过 10 部时,这一比例进一步升至 48.1% 和 17%。
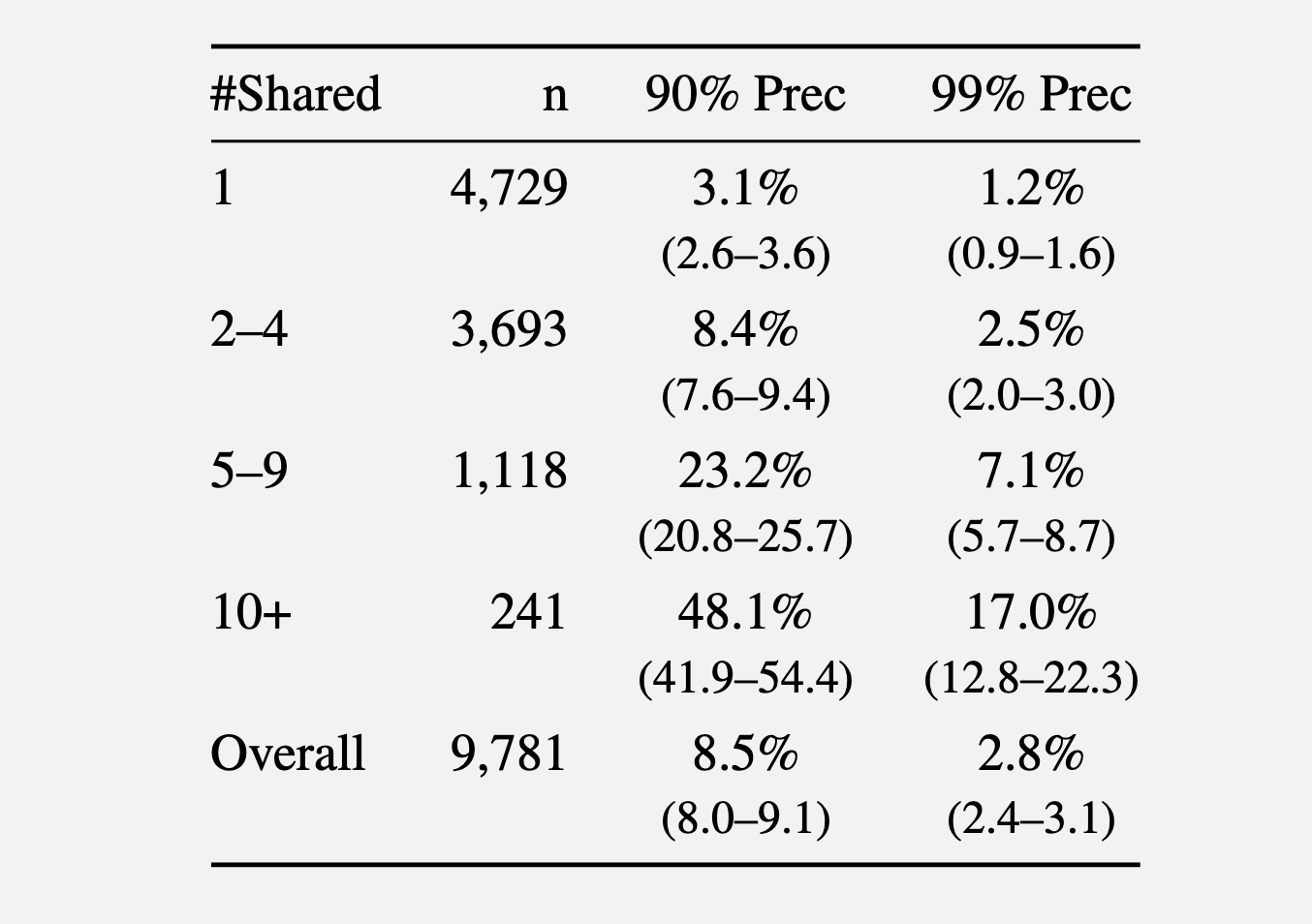
不同 precision 阈值下的召回率。
不同 precision 阈值下的召回率。
在第三项实验中,研究人员选取了 5,000 名 Reddit 用户作为样本,并向候选池加入 5,000 个 Reddit 用户“干扰身份”。研究人员将其方法与较早的 Netflix Prize attack 进行了对比。随后,他们又在总计 10,000 个候选画像中加入 5,000 个“查询干扰项”(query distractors):这些用户只出现在查询集合中,在候选池里并不存在真实匹配对象。