AI Gateway 上线模型实时性能指标:网站与 REST API 均可查看

2 分钟阅读
2026 年 1 月 26 日
AI Gateway 现在可展示数百个模型的吞吐与延迟指标,基于实时性能数据帮助你选择更合适的模型。
这些指标会出现在三个位置,并且每小时更新一次:
-
模型列表:每个模型的最佳性能(P50 latency 和 throughput)
-
模型详情页:按提供商拆分的性能明细
-
REST API:滚动聚合的端点性能数据(latency 和 throughput,P50/P95)
Link to heading模型列表
AI Gateway 的模型列表现在新增了可排序的 latency 和 throughput 列。每一行都会展示该模型在所有可用提供商中的最佳 P50 指标(最低延迟、最高吞吐)。这些指标每小时更新,且基于 AI Gateway 客户的实时请求数据。
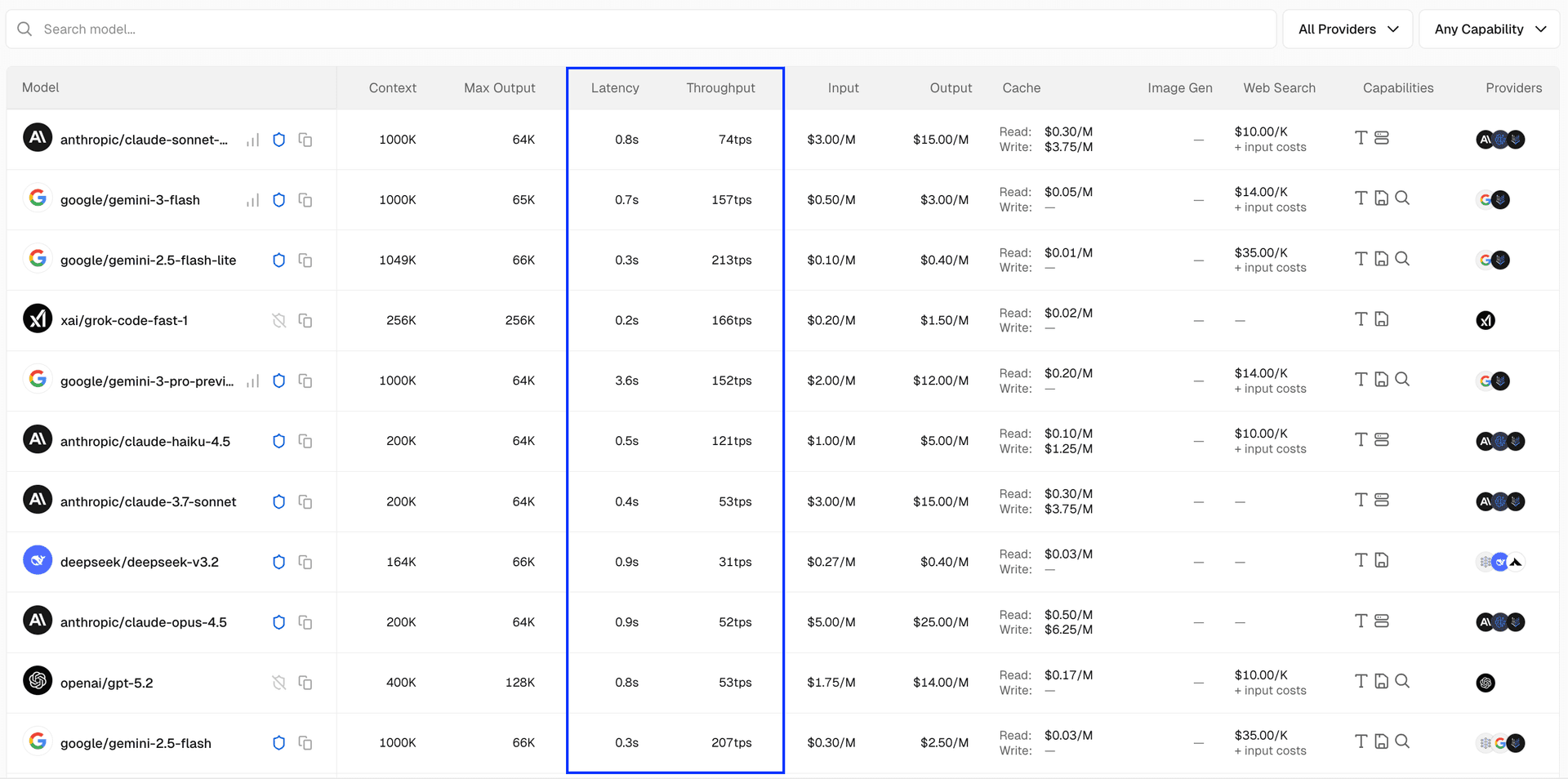
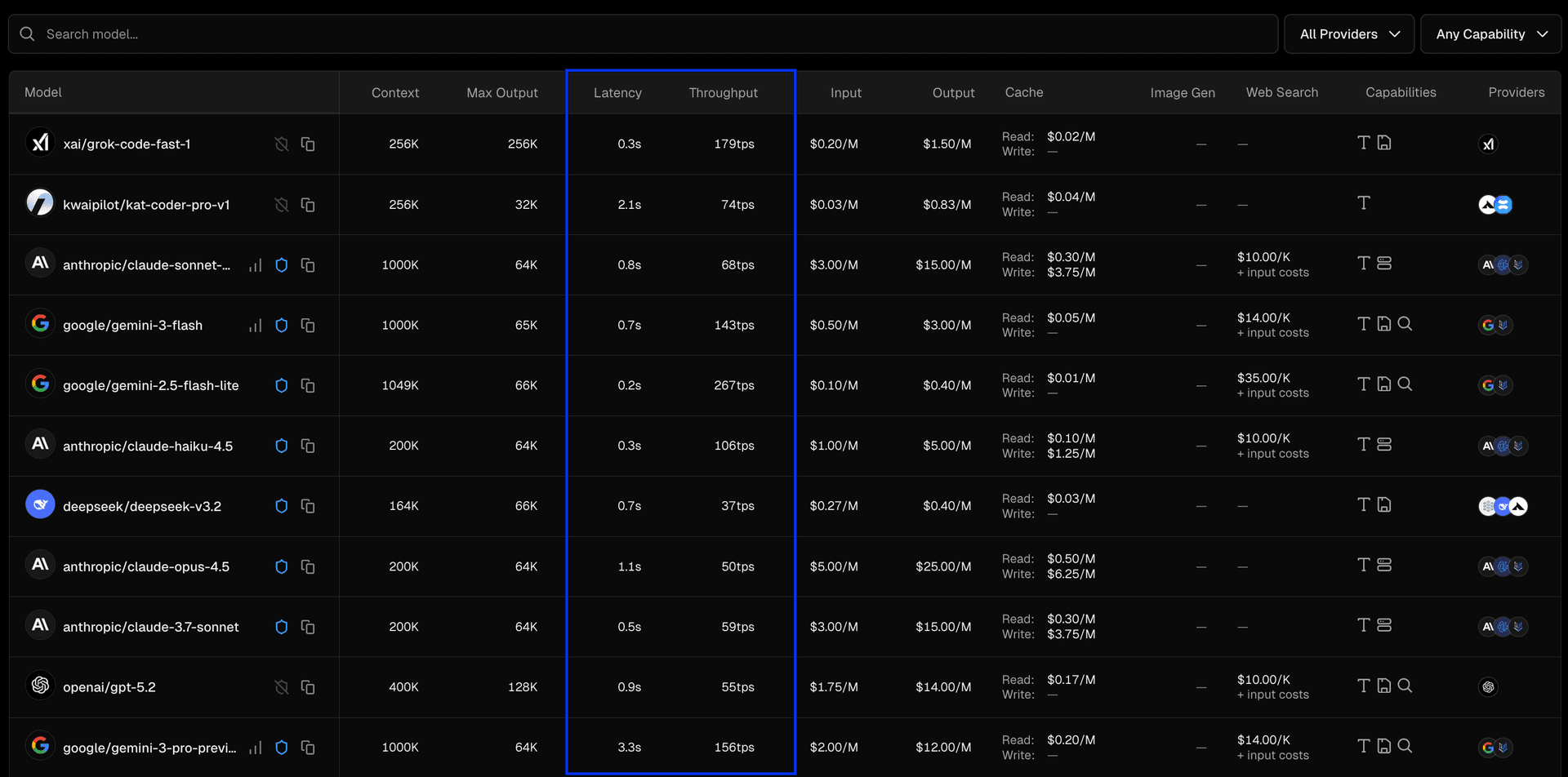
你可以按 throughput 排序来找到 Token 生成速度最快的模型,也可以按 latency 排序来找到首 Token 返回时间(time-to-first-token)最短的模型。
Link to heading模型详情页
在单个模型页面中,你可以看到每个有记录使用量的提供商对应的 P50 latency 和 throughput。这有助于你比较同一模型在不同提供商上的性能,并为你的使用场景选出最佳方案。
要访问这些页面,请在模型列表中点击任意模型,即可查看该模型在 AI Gateway 中所有承载提供商的更细粒度拆分数据。指标按小时刷新,且仅在提供商流量达到一定规模时显示。
下面是 openai/gpt-oss-120b 的示例:
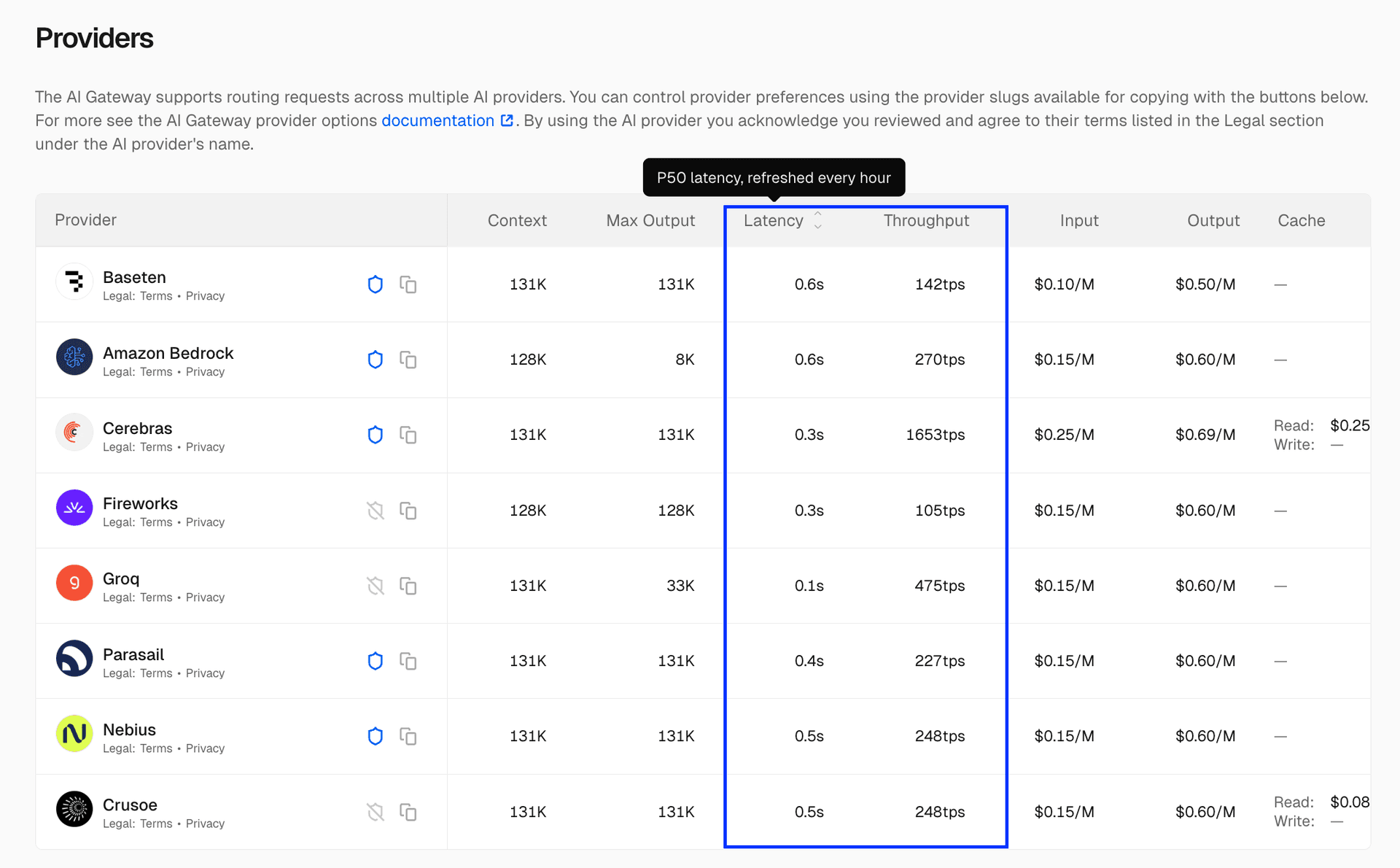
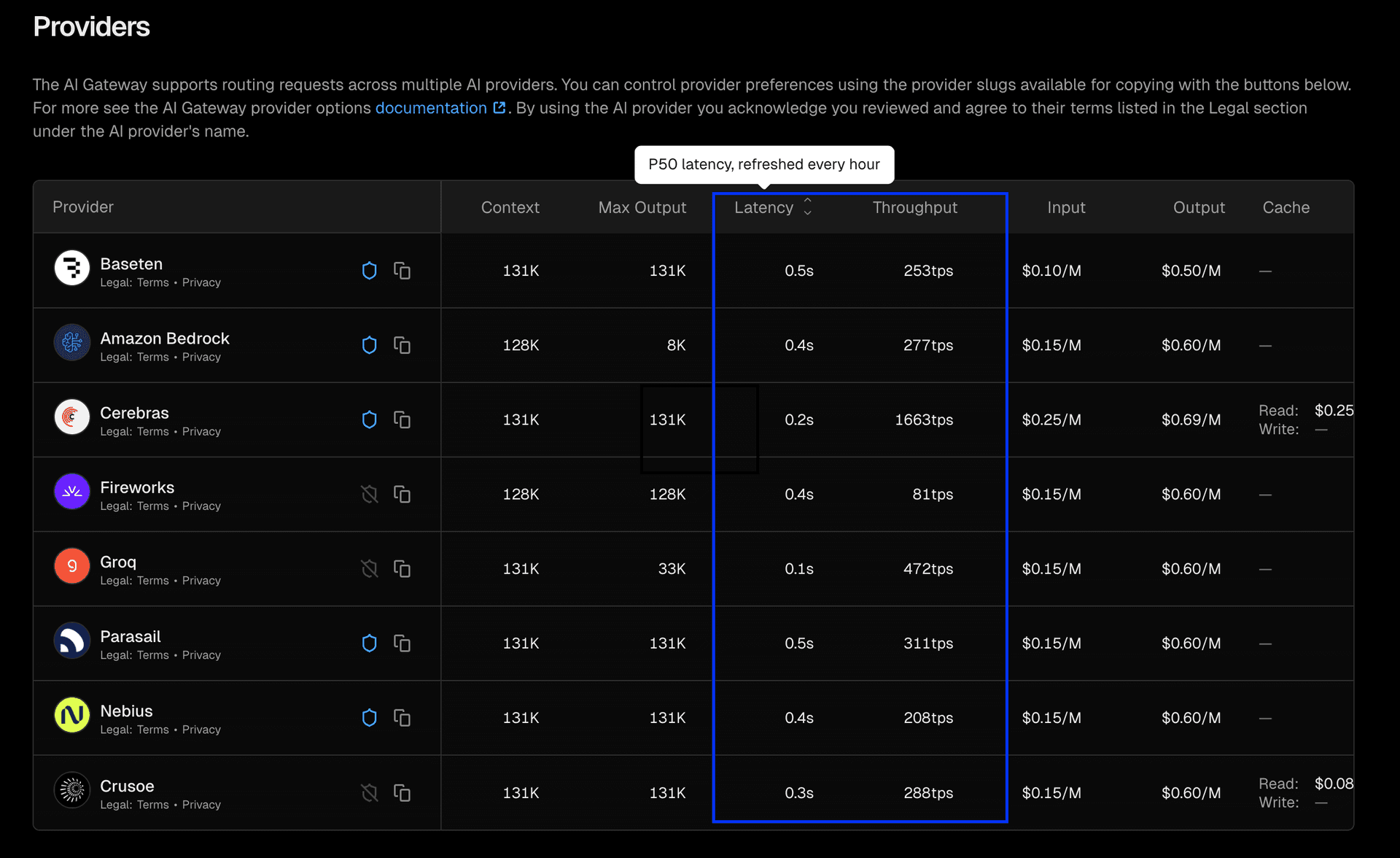
与整体模型列表类似,在模型详情页中你也可以按 latency 和 throughput 在不同提供商之间进行排序。
Link to headingREST API
这些指标也可以通过 endpoints REST API 以编程方式获取。使用时,将 [ai-gateway-string] 替换为目标模型的 creator/model-name。
curl ai-gateway.vercel.sh/v1/models/[ai-gateway-string]/endpoints
该接口会返回指定模型按提供商划分的实时小时级 P50/P95 latency(ms TTFT)与 throughput(T/s)。下面是 zai/glm-4.7 在 Cerebras 提供商下的 endpoint 返回示例。
curl ai-gateway.vercel.sh/v1/models/zai/glm-4.7/endpoints
{ "name": "cerebras | zai/glm-4.7", "latency_last_1h": { "p50": 456.5, "p95": 774.95 }, "throughput_last_1h": { "p50": 354, "p95": 445.45 }, }
如果你想查询完整模型列表,也可以将模型指标 endpoint 与 https://ai-gateway.vercel.sh/v1/models 结合使用。
原文链接:https://vercel.com/changelog/live-model-performance-metrics-accessible-via-ai-gateway