HealthBench 发布:面向医疗 AI 的真实场景评测基准
资讯OpenAI2025-05-12T10:30:00+00:001 分钟阅读
HealthBench 是一项面向医疗 AI 的全新评测基准,用于在真实场景中评估模型表现。该基准在 250 多位医生的参与下构建,目标是为医疗场景中的模型性能与安全性提供一套共享标准。
HealthBench 是一项面向医疗 AI 的全新评测基准,用于在真实场景中评估模型表现。该基准在 250 多位医生的参与下构建,目标是为医疗场景中的模型性能与安全性提供一套共享标准。
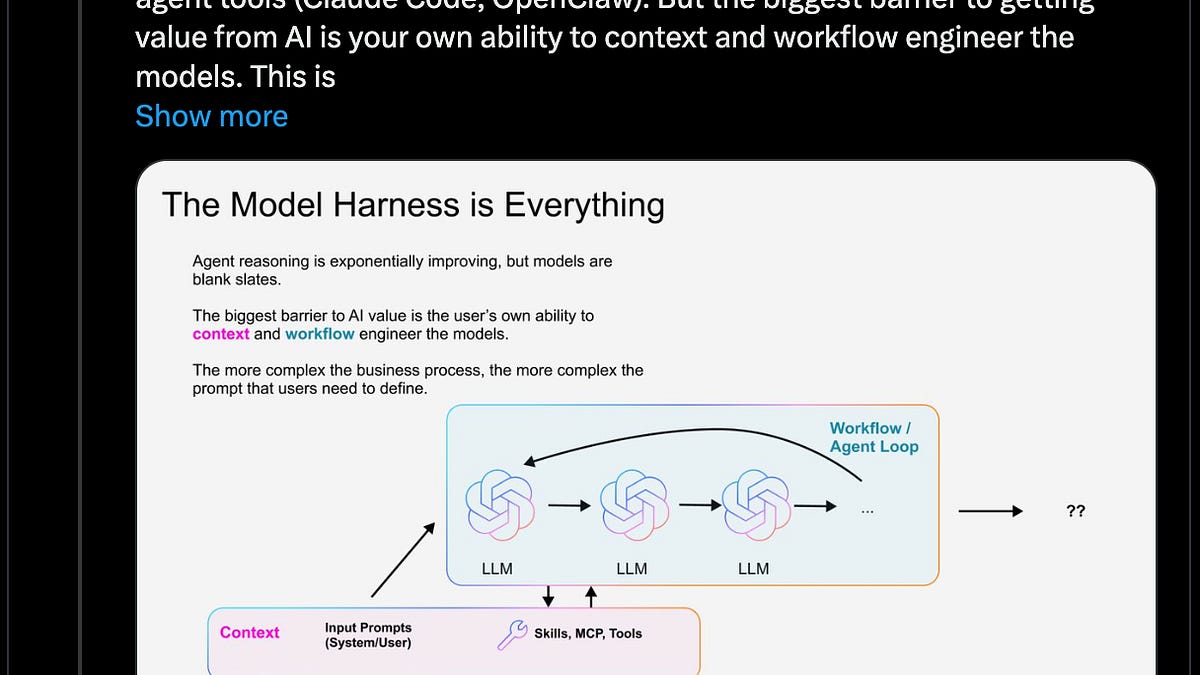
这篇文章围绕 AI 工程中的核心争议展开:系统能力究竟主要来自更强的模型(Big Model),还是来自更强的编排层(Big Harness)。文中汇总了 OpenAI、Anthropic、Scale AI、METR 等多方观点与数据,显示两派在“模型进步会不会吞噬 Harness 价值”上分歧明显。作者最终认为,随着 Agent 产品落地加速,Harness Engineering 的独立价值正在被市场和社区进一步确认。

在围绕“AI 是否正在杀死 SaaS”的争论中,Box CEO Aaron Levie 提出相反观点:企业内容与文件系统在 Agent 时代反而更关键。随着 Filesystem、Sandbox 和 Agent 工作流快速普及,核心问题从“让 Agent 能做事”转向“如何治理 Agent 的身份、权限与安全边界”。他认为,未来企业将拥有远多于人的 Agent 数量,而真正的竞争力在于率先完成面向 Agent 的组织与基础设施改造。