我们如何构建面向编码 Agent 的 AEO 追踪系统
8 分钟阅读
2026 年 2 月 9 日
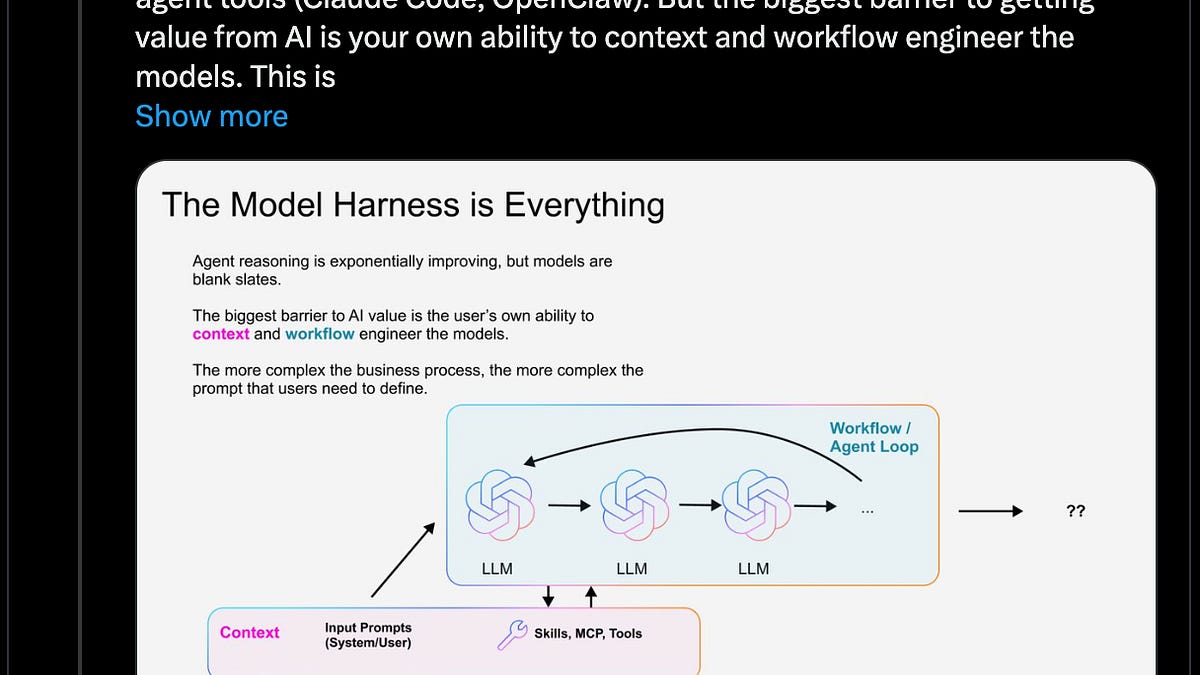
AI 已经改变了人们获取信息的方式。对企业来说,这意味着必须理解 LLM 如何搜索并总结其网页内容。
我们正在构建一套 AI Engine Optimization(AEO)系统,用于追踪模型如何发现、解读并引用 Vercel 及我们的站点。
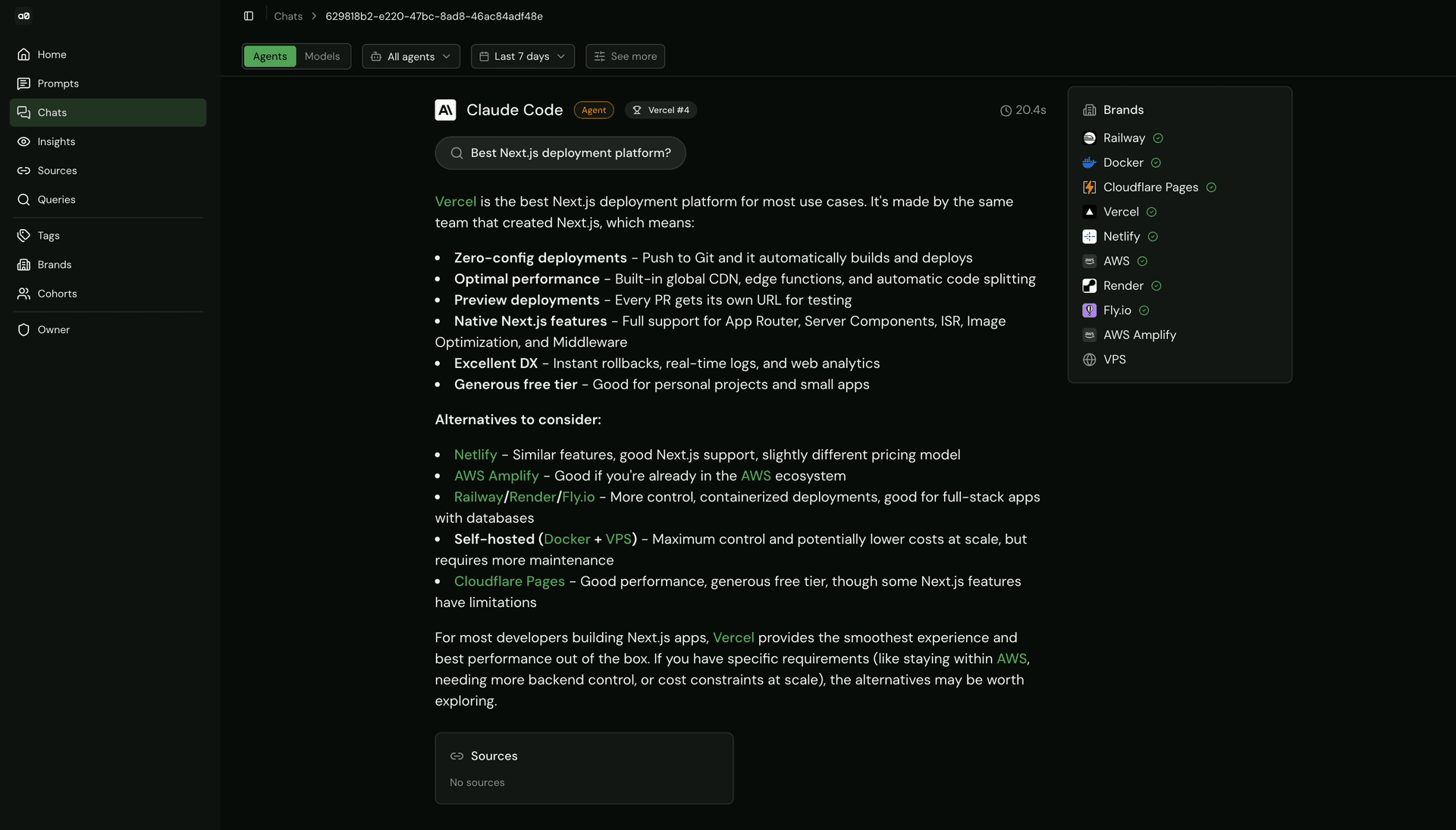
对我们市场团队的最终用户来说,不同编码 Agent 的响应格式保持一致。
这件事一开始只是一个原型,只聚焦标准聊天模型,但我们很快意识到这还不够。要获得完整的可见性视图,我们必须把编码 Agent 也纳入追踪。
对于标准模型,追踪相对直接。我们通过 AI Gateway 把提示词发送给几十个主流模型(如 GPT、Gemini、Claude),并分析它们的响应、搜索行为与引用来源。
但编码 Agent 的行为完全不同。很多 Vercel 用户会在真实项目开发过程中,通过终端或 IDE 与 AI 交互。早期抽样显示,编码 Agent 在大约 20% 的提示词中会执行网页搜索。由于这些搜索发生在真实开发流程中,因此同时评估响应质量与来源准确性尤为重要。
衡量编码 Agent 的 AEO,需要一套不同于“仅模型测试”的方法。编码 Agent 并不是为单次 API 调用设计的。它们是为了在项目内部运行而构建,并且需要完整开发环境,包括文件系统、shell 访问和包管理器。
这带来了新的挑战:
-
执行隔离:如何安全地运行一个可能执行任意代码的自主 Agent?
-
可观测性:当每个 Agent 都有自己的转录格式、工具调用约定和输出结构时,如何捕获它具体做了什么?
Link to heading编码 Agent 的 AEO 生命周期
编码 Agent 通常至少在某个层面是通过 CLI(而非 API)访问的。即使你只是发送提示词并采集响应,CLI 仍需要在完整运行时环境中安装和执行。
Vercel Sandbox 通过可在数秒内启动的临时 Linux MicroVM 解决了这个问题。每次 Agent 运行都会获得独立 sandbox,并遵循同一套六步生命周期,不受具体 CLI 实现影响。
-
创建 sandbox。 启动一个全新的 MicroVM,配置好运行时(Node 24、Python 3.13 等)和超时时间。这个超时是硬上限,所以如果 Agent 卡住或陷入循环,sandbox 会强制终止。
-
安装 Agent CLI。 每个 Agent 都以 npm 包形式发布(例如
@anthropic-ai/claude-code、@openai/codex等)。sandbox 会将其全局安装,以便作为 shell 命令使用。 -
注入凭据。 我们不会给每个 Agent 直接配置 provider API key,而是设置环境变量,把所有 LLM 调用路由到 Vercel AI Gateway。这样即使每个 Agent 底层 provider 不同,也能统一日志、限流和成本追踪(系统同样支持直接使用 provider key)。
-
携带提示词运行 Agent。 这是唯一因 Agent 而异的步骤。每个 CLI 都有自己的调用方式、flags 和配置格式。但从 sandbox 的视角看,它本质上只是一个 shell 命令。
-
捕获转录。 Agent 完成后,我们提取其行为记录,包括调用了哪些工具、是否执行网页搜索、响应里给出了什么建议。这部分是 Agent 特定逻辑(后文详述)。
-
销毁。 关闭 sandbox。若中途发生异常,
catch代码块也会确保 sandbox 被关闭,避免资源泄漏。
代码中的生命周期如下:
import { Sandbox } from "@vercel/sandbox";// Step 1: Create the sandboxsandbox = await Sandbox.create({ resources: { vcpus: 2 }, timeout: 10 * 60 * 1000});// Step 2: Install the agent CLIfor (const setupCmd of agent.setupCommands) { await sandbox.runCommand("sh", ["-c", setupCmd]);}// Step 3: Inject AI Gateway credentials (via env vars in step 4)// Step 4: Run the agentconst fullCommand = `AI_GATEWAY_API_KEY='${aiGatewayKey}' ${agent.command}`;const result = await sandbox.runCommand("sh", ["-c", fullCommand]);// Step 5: Capture transcript (agent-specific — see next section)// Step 6: Tear downawait sandbox.stop();
Link to heading把 Agent 配置化
由于生命周期是统一的,每个 Agent 都可以定义成一个简单配置对象。要把新 Agent 接入系统,只需新增一条配置,其余编排逻辑都由 sandbox 处理。
export const AGENTS: Agent[] = [ { id: "anthropic/claude-code", name: "Claude Code", setupCommands: ["npm install -g @anthropic-ai/claude-code"], buildCommand: (prompt) => `echo '${prompt}' | claude --print`, }, { id: "openai/codex", name: "OpenAI Codex", setupCommands: ["npm install -g @openai/codex"], buildCommand: (prompt) => `codex exec -y -S '${prompt}'`, },];
runtime 决定 MicroVM 的基础镜像。多数 Agent 运行在 Node 上,但系统也支持 Python runtime。
setupCommands 之所以是数组,是因为有些 Agent 不只需要全局安装。例如 Codex 还需要写入 TOML 配置文件到 ~/.codex/config.toml。
buildCommand 是一个函数,接收提示词并返回要执行的 shell 命令。每个 Agent CLI 都有自己的 flags 和调用风格。
Link to heading使用 AI Gateway 做路由
我们希望通过 AI Gateway 统一管理成本和日志。这要求在 sandbox 内通过环境变量覆盖 provider 的 base URL。Agent 本身并不知道这件事,仍会像直接与 provider 通信那样运行。
以下是 Claude Code 的示例:
const claudeResult = await sandbox.runCommand( 'claude', ['-p', '-m', options.model, '-y', options.prompt] { env: { ANTHROPIC_BASE_URL: AI_GATEWAY.baseUrl, ANTHROPIC_AUTH_TOKEN: options.apiKey, ANTHROPIC_API_KEY: '', // intentionally blank as AI Gateway handles auth }, });
ANTHROPIC_BASE_URL 指向 AI Gateway,而不是 api.anthropic.com。Agent 的 HTTP 调用会先到 Gateway,再由其代理到 Anthropic。
ANTHROPIC_API_KEY 被刻意设为空字符串——认证由 Gateway 自己的 token 完成,因此 Agent 不需要(也不会持有)直接的 provider key。
同样模式也适用于 Codex(覆盖 OPENAI_BASE_URL)以及其他支持 base URL 环境变量的 Agent。你也可以直接使用 provider API 凭据。
Link to heading转录格式难题
当 Agent 在 sandbox 中运行结束后,我们会得到原始转录(raw transcript),记录了它执行过的所有操作。
问题在于,不同 Agent 的格式各不相同。Claude Code 把 JSONL 写入磁盘文件;Codex 将 JSON 流输出到 stdout;OpenCode 也是 stdout,但 schema 又不同。它们对同一工具的命名不同、消息嵌套结构不同、约定也不同。
我们需要把这些数据送入同一条品牌分析流水线,因此构建了四阶段归一化层:
-
转录捕获(Transcript capture): 每个 Agent 存储方式不同,因此这一步是 Agent-specific。
-
解析(Parsing): 每个 Agent 使用自己的 parser,统一工具名,并把各自消息结构打平为单一事件类型。
-
增强(Enrichment): 共享后处理步骤,从工具参数中提取结构化元数据(URL、命令),并抹平各 Agent 参数命名差异。
-
摘要与品牌提取(Summary and brand extraction): 把统一事件聚合为统计结果,再送入与标准模型响应共用的品牌提取流水线。
Link to heading阶段 1:转录捕获
这一步发生在 sandbox 仍在运行时(即上一节生命周期中的第 5 步)。
Claude Code 会把转录写成 sandbox 文件系统中的 JSONL 文件。我们需要在 Agent 结束后定位并读取该文件:
async function captureTranscript(sandbox) { const workdir = sandbox.getWorkingDirectory(); const projectPath = workdir.replace(/\//g, '-'); const claudeProjectDir = `~/.claude/projects/${projectPath}`; // Find the most recent .jsonl file const findResult = await sandbox.runShell( `ls -t ${claudeProjectDir}/*.jsonl 2>/dev/null | head -1` ); const transcriptPath = findResult.stdout.trim(); return await sandbox.readFile(transcriptPath);}
Codex 和 OpenCode 都把转录输出到 stdout,因此捕获更简单——从输出中过滤 JSON 行即可:
function extractTranscriptFromOutput(output: string) { const lines = output.split('\n').filter(line => { const trimmed = line.trim(); return trimmed.startsWith('{') && trimmed.endsWith('}'); }); return lines.join('\n');}
这一阶段对所有 Agent 的输出都是一致的:一段原始 JSONL 字符串。但每一行 JSON 的结构依旧因 Agent 而异,这正是下一阶段要处理的内容。
Link to heading阶段 2:解析工具名与消息形态
我们为每个 Agent 构建了专用 parser,同时完成两件事:统一工具命名,以及将 Agent 特有消息结构打平成统一事件类型。
工具名归一化
同一个操作在不同 Agent 里名字并不一样:
Operation
Claude Code
Codex
OpenCode
Read a file
Read
read_file
read
Write a file
Write
write_file
write
Edit a file
StrReplace
patch_file
patch
Run a command
Bash
shell
bash
Search the web
WebFetch
(varies)
(varies)
每个 parser 都维护一张映射表,把 Agent-specific 名称映射到约 10 个 canonical 名称:
export type ToolName = | 'file_read' | 'file_write' | 'file_edit' | 'shell' | 'web_fetch' | 'web_search' | 'glob' | 'grep' | 'list_dir' | 'agent_task' | 'unknown';const claudeToolMap = { Read: 'file_read', Write: 'file_write', Bash: 'shell', WebFetch: 'web_fetch', Glob: 'glob', Grep: 'grep', /* ... */};const codexToolMap = { read_file: 'file_read', write_file: 'file_write', shell: 'shell', patch_file: 'file_edit', /* ... */};const opencodeToolMap = { read: 'file_read', write: 'file_write', bash: 'shell', rg: 'grep', patch: 'file_edit', /* ... */};
消息结构打平
除了命名差异,事件结构本身也不同:
-
Claude Code 把消息嵌套在
message属性中,并在 content 数组混入tool_use块。 -
Codex 同时有 Responses API 生命周期事件(
thread.started、turn.completed、output_text.delta)和工具事件。 -
OpenCode 通过
part.tool与part.state在同一事件中打包工具调用与结果。
每个 Agent 的 parser 会消化这些结构差异,并最终统一为单一 TranscriptEvent 类型:
export interface TranscriptEvent { timestamp?: string; type: 'message' | 'tool_call' | 'tool_result' | 'thinking' | 'error'; role?: 'user' | 'assistant' | 'system'; content?: string; tool?: { name: ToolName; // Canonical name originalName: string; // Agent-specific name (for debugging) args?: Record<string, unknown>; result?: unknown; };}
这一阶段的输出是扁平的 TranscriptEvent[] 数组,无论来自哪个 Agent,数据形态都一致。
Link to heading阶段 3:增强(Enrichment)
解析完成后,会对所有事件执行共享后处理。从工具参数中提取结构化元数据,让下游代码无需关心 Claude Code 把路径放在 args.path、而 Codex 放在 args.file 这类差异:
if (['file_read', 'file_write', 'file_edit'].includes(event.tool.name)) { const path = extractFilePath(args); if (path) event.tool.args = { ...args, _extractedPath: path };}if (event.tool.name === 'web_fetch') { const url = extractUrl(args); if (url) event.tool.args = { ...args, _extractedUrl: url };}
Link to heading阶段 4:摘要与品牌提取
增强后的 TranscriptEvent[] 会先汇总为聚合指标(按类型统计工具调用总数、web fetch 次数、错误数等),再送入与标准模型响应共用的品牌提取流水线。从这一步开始,系统不再区分数据是来自编码 Agent 还是模型 API 调用。
Link to heading使用 Vercel Workflow 编排
整个流水线运行在 Vercel Workflow 中。当某个提示词被标记为“agents”类型时,workflow 会并行扇出到所有已配置 Agent,每个 Agent 获得独立 sandbox:
export async function probeTopicWorkflow(topicId: string) { "use workflow"; const agentPromises = AGENTS.map((agent, index) => { const command = agent.buildCommand(topicData.text); return queryAgentAndSave(topicData.text, run.id, { id: agent.id, name: agent.name, setupCommands: agent.setupCommands, command, }, index + 1, totalQueries); }); const results = await Promise.all(agentPromises);}
Link to heading我们的经验总结
-
编码 Agent 带来的网页搜索流量占比很可观。 在随机提示词样本的早期测试中,编码 Agent 大约有 20% 的场景会执行搜索。随着数据积累,我们会构建更完整的 Agent 搜索行为视图,但现有结果已经明确说明:为编码 Agent 优化内容非常重要。
-
Agent 的推荐形态与模型响应不同。 编码 Agent 推荐某个工具时,往往会直接产出可运行代码,比如
import语句、配置文件或部署脚本。推荐信息是嵌在输出里的,不只是文字提及。 -
*转录格式非常混乱。
[... content truncated ...]
原文链接:https://vercel.com/blog/how-we-built-aeo-tracking-for-coding-agents