从本地模型到 Agent 工作流:用 Microsoft Agent Framework 与 Foundry Local 构建 Deep Research 方案
引言:AI 应用开发的新范式
在企业级 AI 应用开发中,我们经常会遇到这样一个两难:云端大语言模型虽然能力强大,但数据隐私、网络时延和成本控制等问题,让很多场景难以真正落地。传统本地小模型虽然轻量,却缺乏完整的开发、评估与编排框架。
Microsoft Foundry Local 与 Agent Framework(MAF)的组合,为这一难题提供了优雅解法。本文将带你从 0 到 1 搭建完整的 Deep Research Agent 工作流,覆盖从模型安全评估、工作流编排、交互式调试到性能优化的全流程。
为什么选择 Foundry Local?
Foundry Local 不只是本地模型运行时,更是 Microsoft AI 生态向边缘侧的延伸:
- 隐私优先:所有数据与推理过程都在本地完成,满足严格合规要求
- 零延迟:无需网络往返,适合实时交互场景
- 成本可控:避免云 API 调用费用,适合高频调用场景
- 快速迭代:本地开发与调试,缩短反馈周期
结合 Microsoft Agent Framework,你可以像使用 Azure OpenAI 一样构建复杂 Agent 应用。
示例代码:
agent = FoundryLocalClient(model_id="qwen2.5-1.5b-instruct-generic-cpu:4").as_agent(
name="LocalAgent",
instructions="""You are an assistant.
Your responsibilities:
- Answering questions and providing professional advice
- Helping users understand concepts
- Offering users different suggestions
""",
)
如何评估一个 Agent? 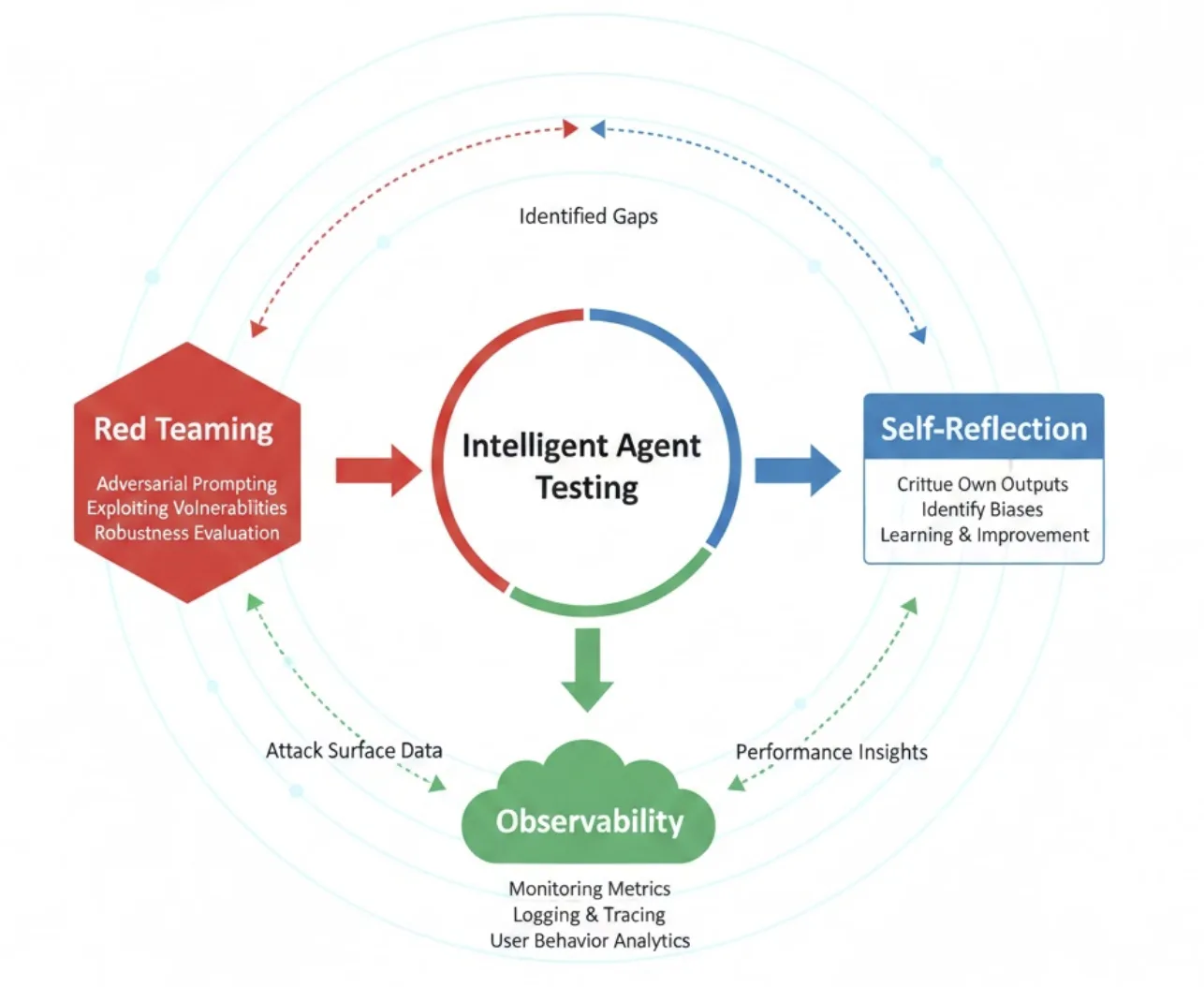
基于 Agent Framework 的评估示例,这里有三种互补的评估方法,并且在该仓库中都提供了对应实现与配置:
-
Red Teaming(安全与鲁棒性)
- 目的:通过系统化对抗提示覆盖高风险内容,测试 Agent 的安全边界。
- 方法:对目标 Agent 执行多种攻击策略,覆盖暴力、仇恨/不公平、性内容、自残等风险类别。
-
Self-Reflection(质量校验)
- 目的:让 Agent 对自身输出进行二次审查,检查事实一致性、覆盖度、引用完整性与答案结构。
- 方法:在任务输出后增加“反思轮次”,Agent 按固定维度给出自评与改进建议,并产出修订版本。
- 该内容在示例中暂时省略
-
Observability(性能度量)
- 目的:借助指标与分布式追踪,衡量端到端时延、分阶段耗时和工具调用开销。
- 方法:启用 OpenTelemetry 上报工作流执行过程与工具调用。
完整开发流程:从安全到生产
第一步:Red Team 评估 —— 夯实安全基线
在任何模型上线前,安全评估都是必要步骤。MAF 提供开箱即用的 Red Teaming 能力,并可结合 Microsoft Foundry 完成 Red Team 评估:
# 01.foundrylocal_maf_evaluation.py
from azure.ai.evaluation.red_team import AttackStrategy, RedTeam, RiskCategory
from azure.identity import AzureCliCredential
from agent_framework_foundry_local import FoundryLocalClient
credential = AzureCliCredential()
agent = FoundryLocalClient(model_id="qwen2.5-1.5b-instruct-generic-cpu:4").as_agent(
name="LocalAgent",
instructions="""You are an assistant.
Your responsibilities:
- Answering questions and providing professional advice
- Helping users understand concepts
- Offering users different suggestions
""",
)
def agent_callback(query: str) -> str:
async def _run():
return await agent.run(query)
response = asyncio.get_event_loop().run_until_complete(_run())
return response.text
red_team = RedTeam(
azure_ai_project=os.environ["AZURE_AI_PROJECT_ENDPOINT"],
credential=credential,
risk_categories=[
RiskCategory.Violence,
RiskCategory.HateUnfairness,
RiskCategory.Sexual,
RiskCategory.SelfHarm,
],
num_objectives=2,
)
results = await red_team.scan(
target=agent_callback,
scan_name="Qwen2.5-1.5B-Agent",
attack_strategies=[
AttackStrategy.EASY,
AttackStrategy.MODERATE,
AttackStrategy.CharacterSpace,
AttackStrategy.ROT13,
AttackStrategy.UnicodeConfusable,
AttackStrategy.CharSwap,
AttackStrategy.Morse,
AttackStrategy.Leetspeak,
AttackStrategy.Url,
AttackStrategy.Binary,
AttackStrategy.Compose([AttackStrategy.Base64, AttackStrategy.ROT13]),
],
output_path="Qwen2.5-1.5B-Redteam-Results.json",
)
评估维度:
- 风险类别:暴力、仇恨/不公平、性内容、自残
- 攻击策略:编码混淆、字符替换、Prompt 注入等
- 输出分析:生成详细风险评分卡与响应样本
评估结果会以 JSON 保存,便于追溯与持续监控。这一步可确保模型在面对恶意输入时具备足够鲁棒性。
这是运行 01.foundrylocal_maf_evaluation.py 后的截图。你可以通过调整 Prompt 进一步优化结果。

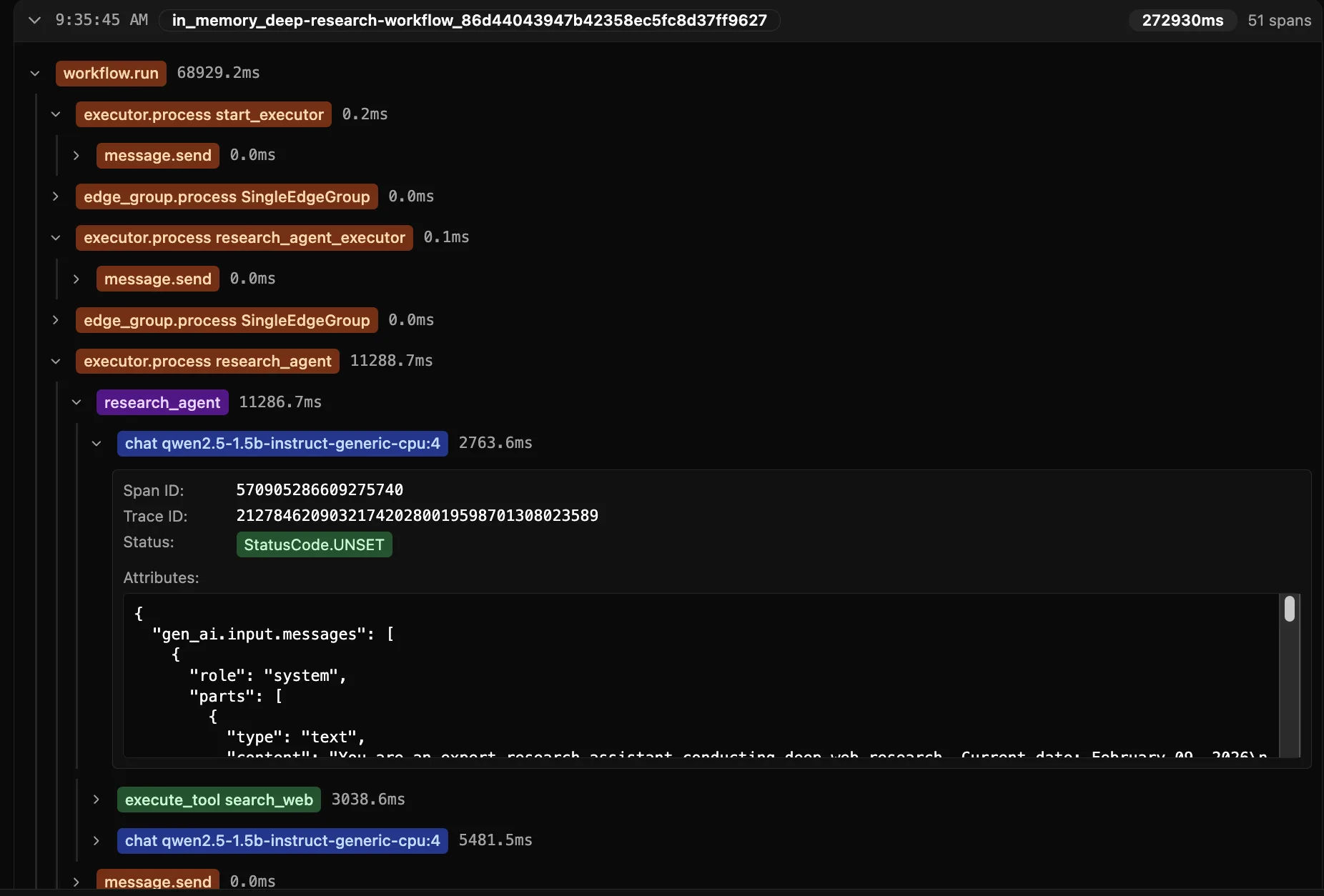
第二步:Deep Research 工作流设计 —— 多轮迭代智能
Deep Research 的核心是“研究—判断—再研究”的迭代闭环。借助 MAF Workflows,这套复杂逻辑可以变得清晰且可维护:
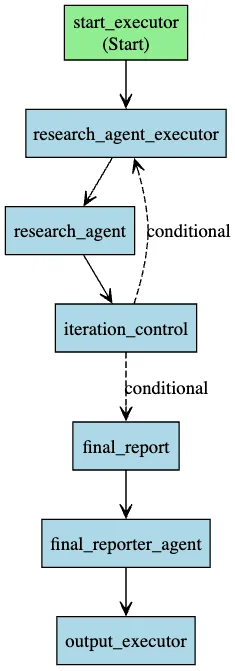
关键组件:
-
Research Agent
- 配备
search_web工具,实时检索外部信息 - 每一轮生成摘要并识别知识缺口
- 累积上下文,避免重复搜索
- 配备
-
Iteration Controller
- 评估当前信息完整性
- 决策分流:继续深挖 vs 生成报告
- 防止无限循环(设置最大轮次)
-
Final Reporter
- 汇总所有轮次结果
- 生成带引用的结构化报告
代码实现(简化):
from agent_framework import WorkflowBuilder
from agent_framework_foundry_local import FoundryLocalClient
workflow_builder = WorkflowBuilder(
name="Deep Research Workflow",
description="Multi-agent deep research workflow with iterative web search"
)
workflow_builder.register_executor(lambda: StartExecutor(state=state), name="start_executor")
workflow_builder.register_executor(lambda: ResearchAgentExecutor(), name="research_executor")
workflow_builder.register_executor(lambda: iteration_control, name="iteration_control")
workflow_builder.register_executor(lambda: FinalReportExecutor(), name="final_report")
workflow_builder.register_executor(lambda: OutputExecutor(), name="output_executor")
workflow_builder.register_agent(
lambda: FoundryLocalClient(model_id="qwen2.5-1.5b-instruct-generic-cpu:4").as_agent(
name="research_agent",
instructions="...",
tools=search_web,
default_options={"temperature": 0.7, "max_tokens": 4096},
),
name="research_agent",
)
workflow_builder.add_edge("start_executor", "research_executor")
workflow_builder.add_edge("research_executor", "research_agent")
workflow_builder.add_edge("research_agent", "iteration_control")
workflow_builder.add_edge(
"iteration_control",
"research_executor",
condition=lambda decision: decision.signal == ResearchSignal.CONTINUE,
)
workflow_builder.add_edge(
"iteration_control",
"final_report",
condition=lambda decision: decision.signal == ResearchSignal.COMPLETE,
)
workflow_builder.add_edge("final_report", "final_reporter_agent")
workflow_builder.add_edge("final_reporter_agent", "output_executor")
这种设计的优势在于:
- 模块化:每个 executor 单一职责,易测试、易替换
- 可观测:每个节点输入输出都可追踪
- 可扩展:可以方便地加入新工具或决策逻辑
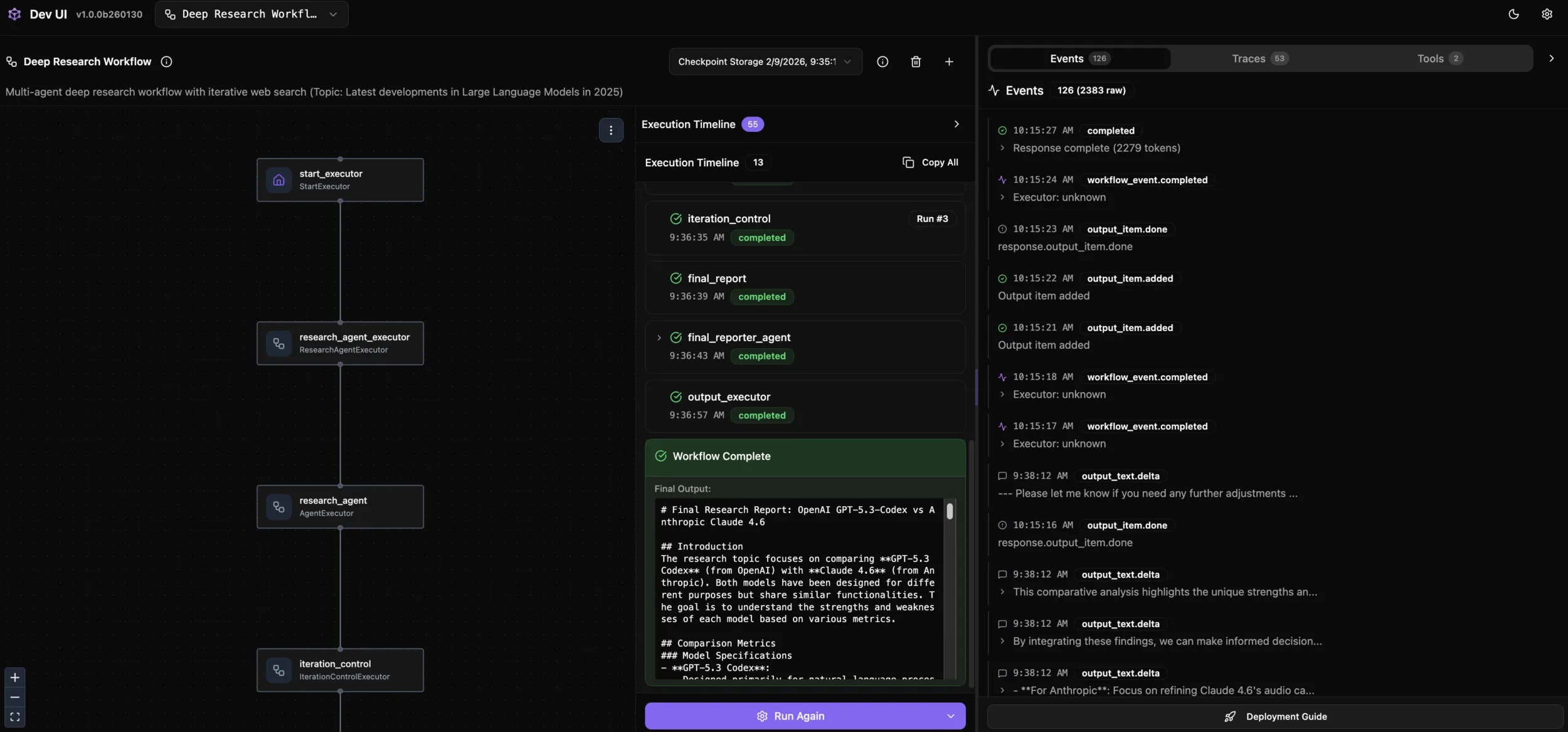
第三步:DevUI 交互式调试 —— 让工作流“可见”
传统 Agent 调试常常像“黑盒”。MAF DevUI 将整个执行过程可视化:
python 02.foundrylocal_maf_workflow_deep_research_devui.py
# DevUI starts at http://localhost:8093
DevUI 提供:
- 工作流拓扑图:直观看到节点与边关系
- 逐步执行视图:查看每个节点输入、输出与状态
- 实时注入:动态修改输入参数,测试不同场景
- 日志聚合:统一查看所有 Agent 日志与工具调用
调试场景示例:
- 输入:“GPT-5.3-Codex vs Anthropic Claud 4.6”
- 观察:Research Agent 在 3 轮中搜索关键词的演进
- 验证:Iteration Controller 的决策依据是否合理
- 检查:最终报告是否覆盖全部子主题
这种交互体验能显著缩短从发现问题到解决问题的时间。
第四步:性能评估与优化 —— 集成 .NET Aspire
在生产环境中,性能是不可忽视的维度。MAF 与 .NET Aspire 的集成提供了企业级可观测性:
启用遥测:
# Configure OpenTelemetry
export OTLP_ENDPOINT="http://localhost:4317"
# Workflow automatically reports
- Latency: Time consumption of each executor
- Throughput: Concurrent request processing capacity
- Tool Usage: search_web call frequency and time consumption
关键指标:
- 端到端时延:从用户输入到最终报告的总耗时
- 模型推理时间:本地模型响应速度
- 工具调用开销:外部 API(如搜索)带来的影响
- 内存占用:多轮迭代上下文累积情况
优化策略:
- 使用更小模型(如 Qwen2.5-1.5B)平衡速度与质量
- 缓存常见搜索结果,减少 API 调用
- 限制迭代深度,避免过度研究
- 采用流式输出提升用户体验
通过分布式追踪,你可以精准定位瓶颈,并基于数据做优化决策。
实战指南:快速开始
GitHub Repo : https://github.com/microsoft/Agent-Framework-Samples/blob/main/09.Cases/FoundryLocalPipeline/
环境准备
# 1. Set environment variables
export FOUNDRYLOCAL_ENDPOINT="http://localhost:8000"
export FOUNDRYLOCAL_MODEL_DEPLOYMENT_NAME="qwen2.5-1.5b-instruct-generic-cpu:4"
export SERPAPI_API_KEY="your_serpapi_key"
export AZURE_AI_PROJECT_ENDPOINT="your_azure_endpoint"
export OTLP_ENDPOINT="http://localhost:4317"
# 2. Azure authentication (for evaluation)
az login
# 3. Install dependencies (example)
pip install azure-ai-evaluation azure-ai-evaluation[redteam] agent-framework agent-framework-foundry-local
三步启动
第 1 步:安全评估
python 01.foundrylocal_maf_evaluation.py
# View results: Qwen2.5-1.5B-Redteam-Results.json
第 2 步:DevUI 模式(推荐)
python 02.foundrylocal_maf_workflow_deep_research_devui.py
# Open in browser: http://localhost:8093
# Enter research topic, observe iteration process
第 3 步:CLI 模式(生产)
python 02.foundrylocal_maf_workflow_deep_research_devui.py --cli
# Directly output final report
架构洞察:从模型到 Agent 的演进
这个案例展示了现代 AI 应用开发的三个层级:
- 模型层(基础):Foundry Local 提供可靠推理能力
- Agent 层:ChatAgent + Tools 封装业务逻辑
- 编排层:MAF Workflows 处理复杂流程
传统开发往往止步于模型调用,而 MAF 让你站在更高抽象层:
- 不再手写循环和状态管理
- 自动处理工具调用与结果解析
- 内置可观测性与错误处理
这种“框架优先”方法,是企业 AI 从 POC 走向生产的关键。
适用场景与扩展方向
当前方案适用于:
- 需要多轮信息整合的研究任务
- 对数据隐私敏感的企业场景
- 高频调用下的成本优化需求
- 离线或弱网环境
扩展方向:
- 多 Agent 协作:增加专家 Agent(如数据分析、代码生成)
- 知识库集成:结合向量数据库检索私有文档
- Human-in-the-Loop:在关键决策点加入人工审核
- 多模态支持:处理图片、PDF 等富媒体输入
结语:本地化 AI 的无限可能
Microsoft Foundry Local + Agent Framework 的组合证明:本地小模型同样可以构建生产级智能应用。通过这个 Deep Research 案例,我们看到:
- 安全可控:Red Team 评估确保模型行为符合预期
- 高效编排:Workflows 让复杂逻辑清晰且可维护
- 快速迭代:DevUI 提供即时反馈,缩