[AINews] 定制 ASIC 论:把模型“烧进”芯片,超高速 LLM 推理正在到来
![[AINews] 定制 ASIC 论:把模型“烧进”芯片,超高速 LLM 推理正在到来](https://substackcdn.com/image/fetch/$s_!AQKx!,w_1200,h_675,c_fill,f_jpg,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F135eb2d4-a2b3-41db-8d80-3456a144fb84_3092x1430.png)
2026/2/19-2026/2/20 的 AI News。我们为你检查了 12 个 subreddit、544 个 Twitter 账号列表 和 24 个 Discord(262 个频道、12582 条消息)。按 200wpm 估算,帮你节省阅读时间 1242 分钟。AINews 官网可搜索所有往期内容。提醒一下,AINews 现已成为 Latent Space 的一个栏目。你也可以在邮件频率上选择订阅/退订!
恭喜 ggml + Huggingface 团队,也建议关注 Opus 4.6 的 METR 争论,以及 Chris Lattner 对 Claude C Compiler 的分析。不过,这些都不是今天的头条。
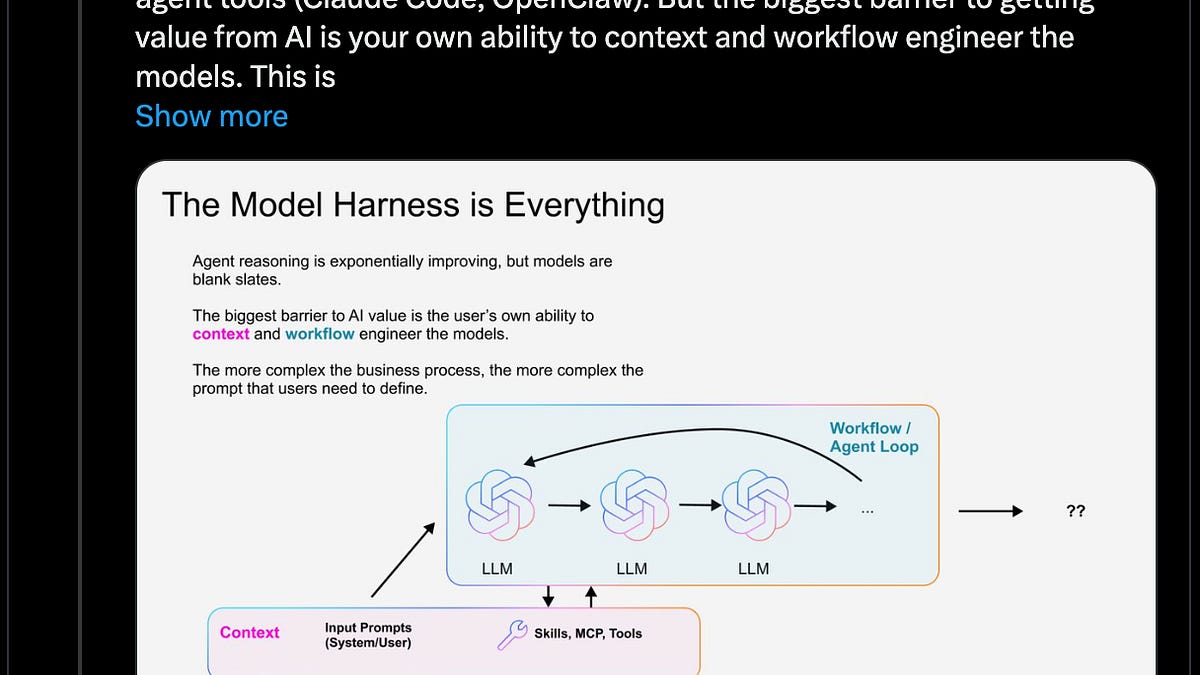
今天,成立仅 2.5 年的 Taalas 宣布:其面向 Llama 3.1 8B(2024 年 7 月发布)的生产 API 服务,实现了每用户惊人的 16,960 tokens/s:
[
除了速度之外,也有一些收益(如更低的构建成本与功耗);但同时也伴随量化层面的注脚(他们提到 HC2 将通过标准化低精度 FP4 来解决)。
这是一个令人印象深刻的结果……但我们还不知道该如何把它真正产品化。 每当出现这种巨大的能力富余窗口,AI 工程师都应该尽快探索其“capability market fit(能力-市场匹配)”。
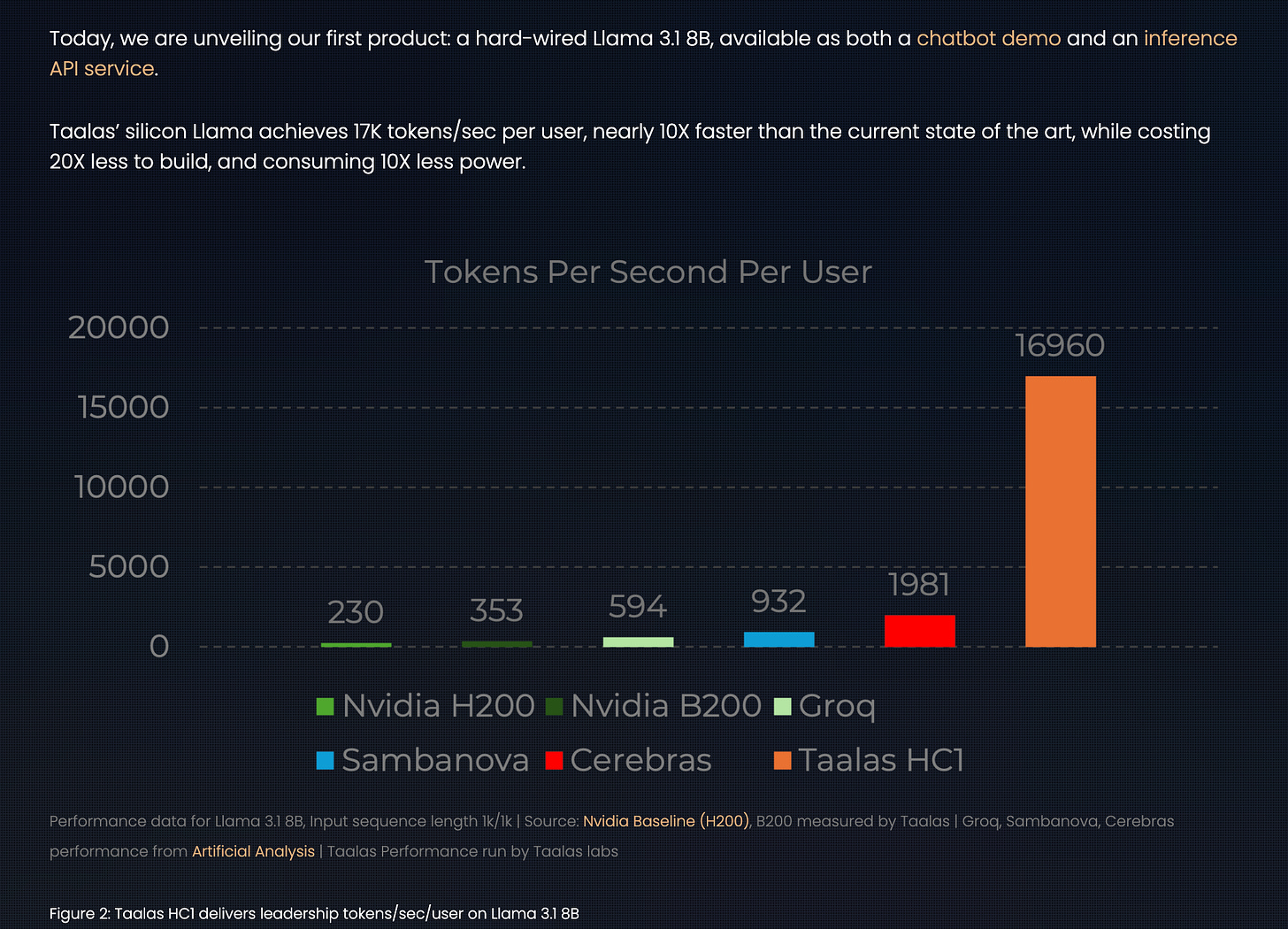
至于“是否应该走定制 ASIC”这一整体命题,我们还在回味本周 Latent Space 与 Martin Casado 和 Sarah Wang 的讨论。Martin 再次强调他对“按模型定制加速器(ASIC)”这套数学账的信心——本质上就是“把 LLM 烧进硅里”,这也呼应了 OpenAI 与 Broadcom 的合作:
Martin: 如果赶得上时间线,做定制 ASIC 实际上是说得通的。现在的问题是时间,不是钱,因为粗略算账如下:
-
如果一次训练要花 10 亿美元,那这个模型的推理收入就必须超过 10 亿,否则就不可持续。
-
假设你能省 20%(而 ASIC 很可能能省得远不止 20%),那就是 2 亿美元。
-
2 亿美元足够你 tape out 一颗芯片。
对吧?所以从经济性上已经能证明可行——不是时间线层面的可行性,那是另一个问题。
swyx: 每个模型一颗 ASIC,因为每次用通用 Nvidia,我们都在浪费这么多性能空间。
Martin Casado: 没错。其实远不止这么多。你可能能拿到 2 倍量级的提升,那就是 5 亿美元。典型 MFU 大概在 50。
我们理解定制芯片的权衡:用更低模型质量(在 Taalas 的例子里,落后前沿约 1.5 年)换取更快、更便宜的推理。但随着 LLM 架构持续标准化,以及更关键的——OpenAI 等公司开始按 Martin 预期推进完全一体化的模型-芯片协同设计,这个差距几乎必然会缩小。现在重点甚至不只是省钱——对今天的 AI 工程师来说,真正前沿质量 + >20,000 tok/s 推理的潜力几乎难以想象。我们应当从现在就开始这类产品与场景的思维实验,并预期在未来不到 2 年内实现。
[
前沿模型评测:Gemini 3.1 Pro、SWE-bench、MRCR 与“分裂式”真实表现
-
Gemini 3.1 Pro 在检索上表现强,但 Agent 可用性评价不一:Context Arena 的 MRCR 更新显示,Gemini 3.1 Pro Preview 在较简单检索任务上几乎追平 GPT‑5.2 (thinking:xhigh)(2‑needle @128k AUC 99.6% vs 99.8%),在更难的多针检索上表现更强(8‑needle @128k AUC 87.8%,高于该处报告的 GPT‑5.2 thinking 档位)(DillonUzar)。另外,Artificial Analysis 提出一个可能被低估的维度:token 效率 + 价格;他们称其 Intelligence Index 套件在 Gemini 3.1 Pro Preview 上成本为 $892,而 GPT‑5.2 xhigh 为 $2,304、Opus 4.6 max 为 $2,486,且在其测试中 Gemini 消耗的 token 也少于 GPT‑5.2(ArtificialAnlys)。
-
但工程师反馈“基准很强,产品偏弱”:多个讨论线程抱怨 Gemini 的工具链/运行框架仍显滞后——例如 CLI 中模型可用性不一致、“Antigravity”里 Agent 行为有 bug,以及令人担忧的“UI 说的是 Gemini,底层返回却是 Claude”的混乱情况(Yuchenj_UW, Yuchenj_UW)。即便有“更快的马”式积极评价,也常与“日常不好用”的挫败感并存(theo)。
-
SWE-bench Verified 的评测方法再次成为关键:MiniMax 提到在相同设置下,对 MiniMax M2.5 的 SWE-bench Verified 结果进行了“独立复核”,暗示此前跨实验室比较可能并不在同一基线上(MiniMax_AI)。Epoch AI 也明确承认了这一失真模式:他们更新了 SWE‑bench Verified 方法论,因为之前的运行方式与他人系统性不同;更新后结果更接近开发者实际报告分数(EpochAIResearch)。
-
基准中的“异常点”正在引发“我们到底在测什么?”:一个例子是——前沿模型“横扫 ARC-AGI”,却在 Connect 4 上表现吃力,这暗示 ARC 风格谜题即便设计目标是抗过拟合,也可能只覆盖了空间/博弈推理的狭窄切面(paul_cal)。另一个线程认为,能在 ARC‑AGI‑3 的“简易 harness”上取得进展的模型可能只有少数,同时指出成本才是主要约束(scaling01, scaling01)。
原文链接:https://www.latent.space/p/ainews-the-custom-asic-thesis