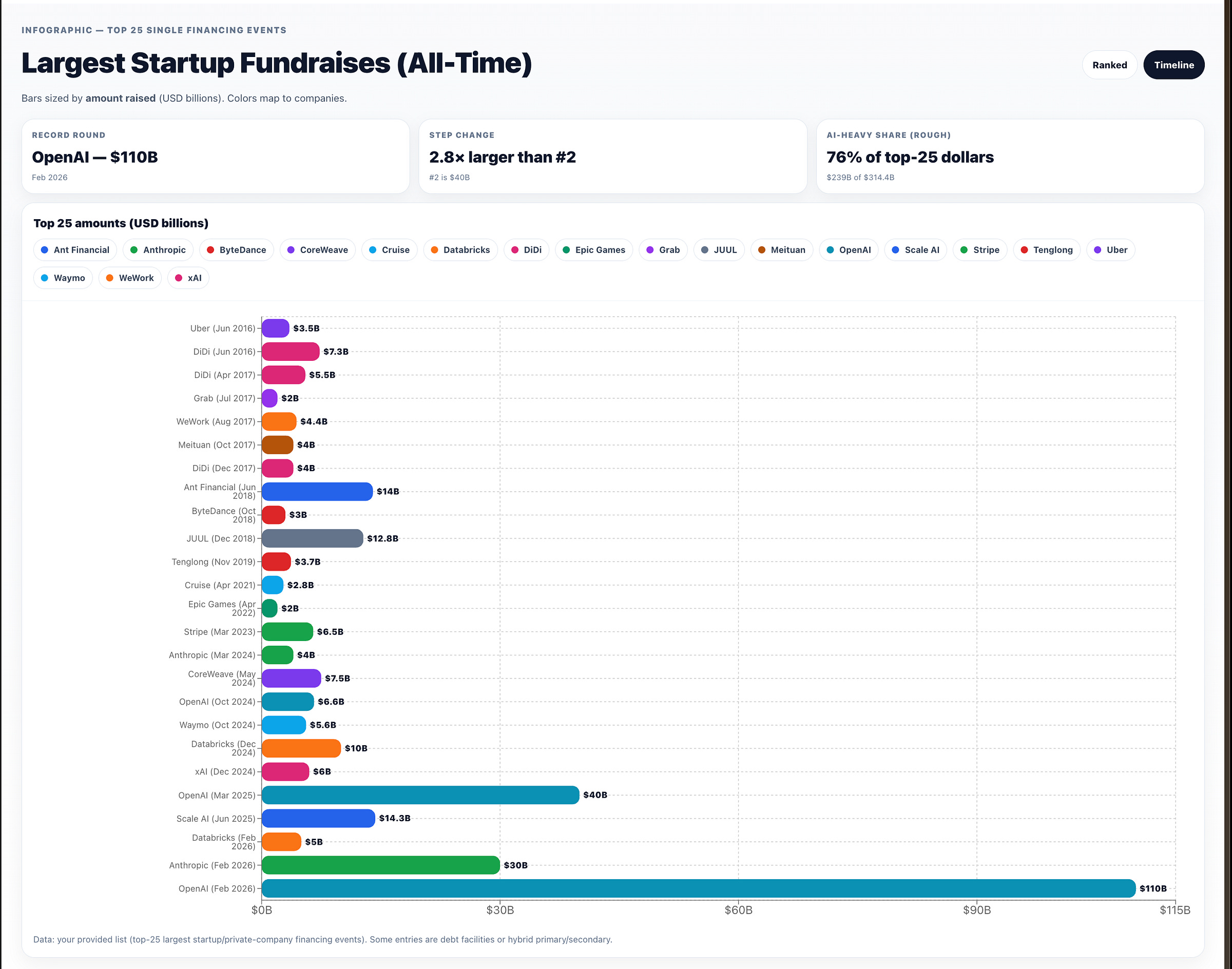
OpenAI完成1100亿美元融资:亚马逊、NVIDIA与软银入局,估值达8400亿美元创纪录
Title: [AINews] OpenAI以8400亿美元投后估值完成史上最大创业融资,获亚马逊、NVIDIA、软银1100亿美元注资
Summary: 恭喜,你拿下了最大的数字。
Content:
2026/2/26-2026/2/27 的 AI 新闻。我们为你检查了 12 个 subreddit、544 个 Twitter 和 24 个 Discord(263 个频道、12529 条消息)。按 200wpm 估算,节省阅读时间 1189 分钟。AINews 网站可检索所有往期内容。提醒一下,AINews 现已成为 Latent Space 的一个栏目。你也可以随时订阅/退订不同邮件频率!
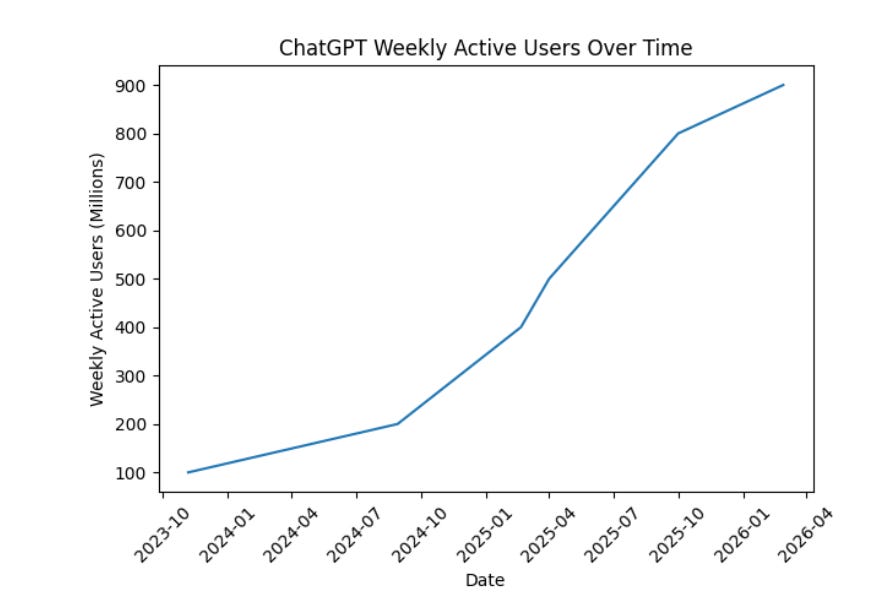
在与“战争部”(Department of War)相关的持续博弈背景下(Anthropic 拒绝条款 vs OpenAI 达成合作),OpenAI 终于官宣完成这轮从去年12月起就备受争议的超级融资。公告中披露了几项值得关注的新数据:
-
Codex 每周用户数年初至今已增长超过3倍,达到 160万
- 2月4日时为100万(!!?!?!)
-
超过900万企业付费用户 依赖 ChatGPT 进行工作
-
ChatGPT 已成为大众接触 AI 的起点:每周活跃用户超9亿,消费者订阅用户现已超过 5000万(1-2月变现仍在加速)
[
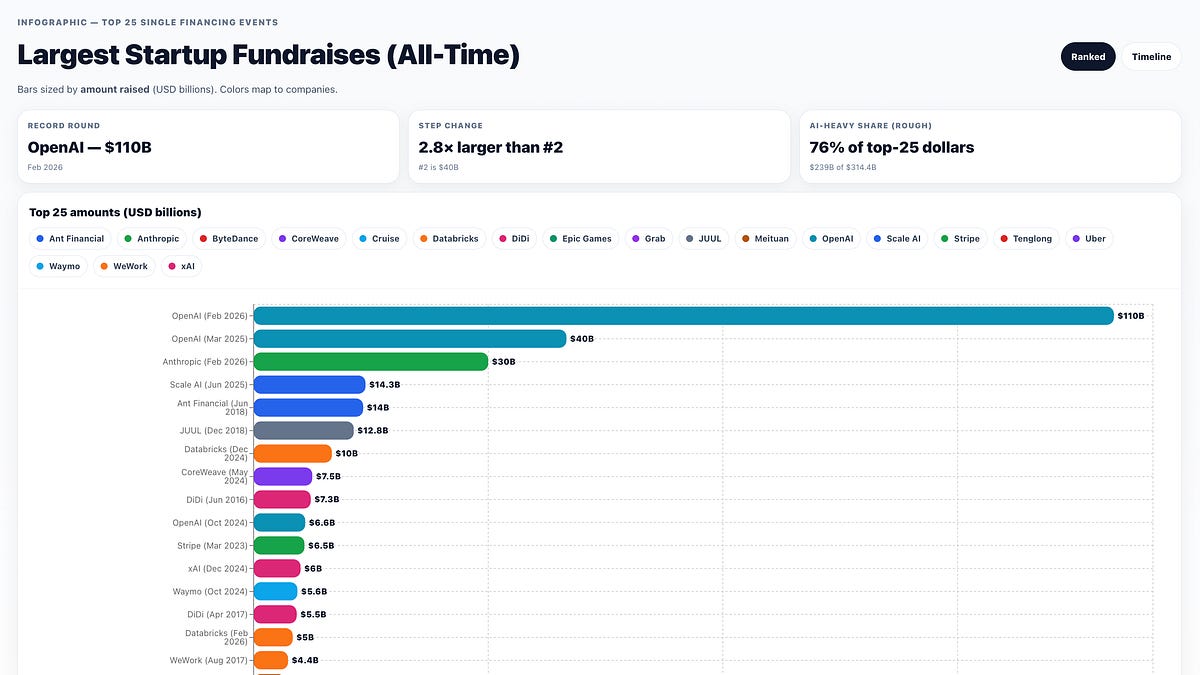
以上数据支撑了这笔 按7300亿美元投前估值完成的1100亿美元新融资:
-
软银出资300亿美元(“推进我们自己的 ASI 战略”);
-
NVIDIA 出资300亿美元(包括 3GW 专用推理算力和 Vera Rubin 系统上的 2GW 训练算力)——低于此前“最高1000亿美元”传闻,但仍存在循环出资疑虑;
-
-
先期投资150亿美元,并在未来数月达成条件后再投入350亿美元——这也让亚马逊在 OpenAI 与 Anthropic 双方都持有较大股份
-
在 Amazon Bedrock 上提供由 OpenAI 支持的“Stateful Runtime Environment”
-
AWS 将成为 OpenAI Frontier 的独家第三方云提供商
-
通过 AWS 基础设施获得 2GW 的 Trainium 算力,号称“8年1000亿美元”,覆盖 Trainium3 与下一代 Trainium4 芯片
-
密切关注者会注意到,微软并未出现在本轮融资中;其与 OpenAI 的关系仍延续现有收缩后的合作模式,并获得无状态 API。
作为对比,全球有 118 个国家/经济体名义 GDP 低于1000亿美元——约占世界经济体总数的61%。连续出现“史上最大融资”,数字已经大到超出直觉,这里给一张配得上 wtfhappened2025.com 的图:
[

以及 AI 之外过去10年的融资历史:
[

以及由 OpenAI Deep Research + ChatGPT Canvas 生成、按融资额降序排列的版本:
[
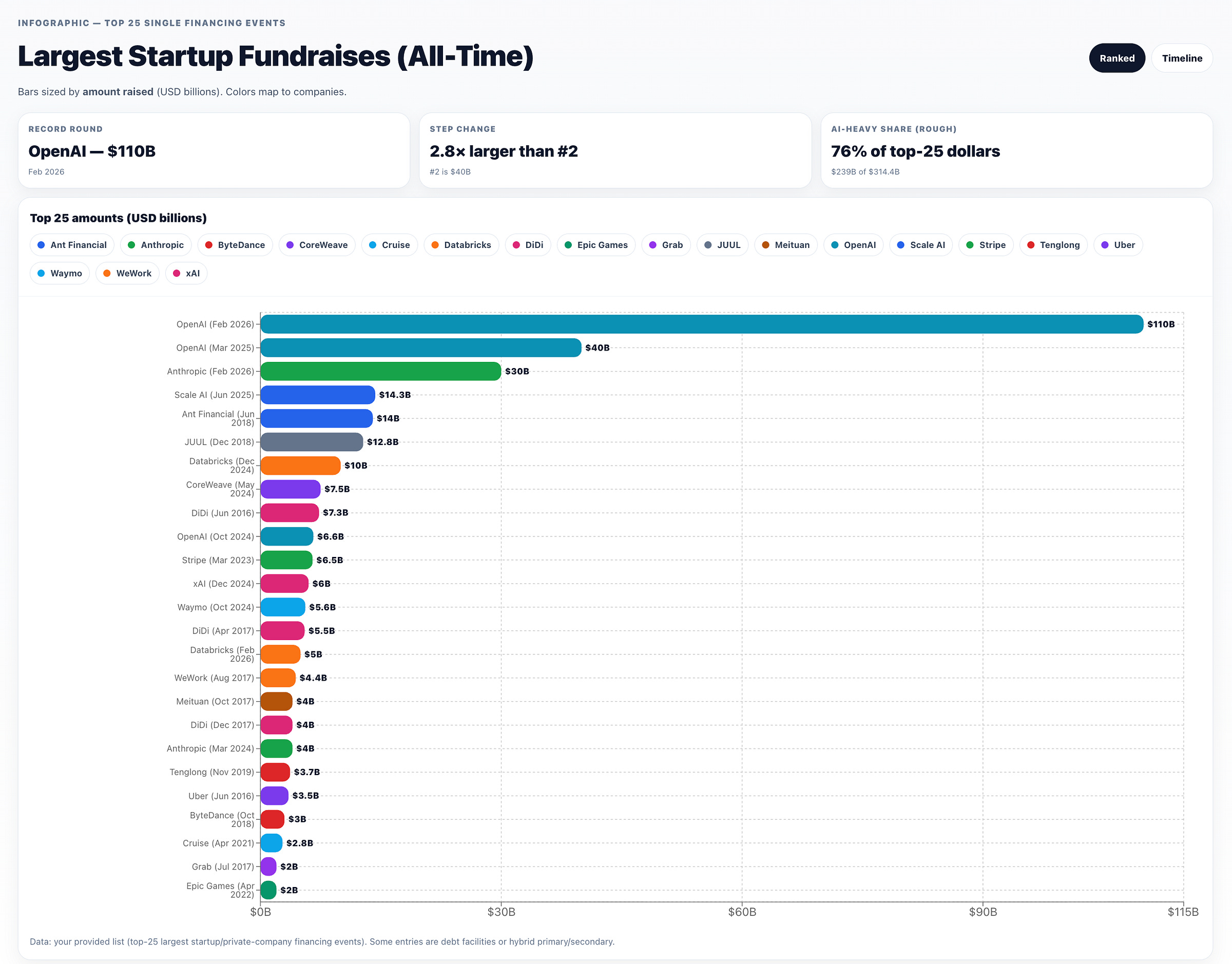
或时间线视角:
[
用于即时 LoRA“编译”的超网络:Doc-to-LoRA + Text-to-LoRA
-
Doc-to-LoRA / Text-to-LoRA(Sakana AI):Sakana 提出两种相关方法,通过训练 hypernetwork 在单次前向中生成 LoRA adapter,从而摊薄定制化成本,把原本需要微调/蒸馏/长上下文提示的过程变成“即时权重更新”。核心主张是:无需把所有信息都放在昂贵的活跃上下文窗口中,而是把任务描述或长文档编译成 adapter 权重,做到亚秒级延迟,实现快速适配与类似“持久记忆”的行为(SakanaAILabs, hardmaru)。
-
Text-to-LoRA:仅根据自然语言描述即可泛化到未见任务(SakanaAILabs)。
-
Doc-to-LoRA:将事实性文档内化;在 needle-in-a-haystack 测试中,据称在约为基础模型上下文窗口5倍的序列上仍接近满分;还展示了跨模态技巧:把 VLM 的视觉信息通过内化权重迁移到纯文本模型中(SakanaAILabs;综述线程 omarsar0)。
-
与长上下文方案的定位差异:明确将其定位为降低二次方 attention 成本、避免每次调用都重复读取长文档——即把知识存进 adapter,而不是 token(omarsar0)。
-
-
署名与先行工作争议:有研究者称,后续相似工作未充分致谢 Hypersteer(即通过 hypernetwork 从文本描述生成 steering vectors)(aryaman2020)。社区层面也出现广泛兴奋反应,“hypernetwork 回来了”(willdepue, zhansheng)。
-
被提出的开放问题:为何不直接用超长 KV cache 的 attention?也就是说,Doc-to-LoRA 的核心价值是否主要在效率/服务成本?(hyhieu226)
OpenAI 融资 + 部署透明度工具
-
1100亿美元融资:OpenAI 宣布完成 1100亿美元 融资,资方包括 Amazon、NVIDIA、SoftBank,并将其定义为扩展基础设施“让 AI 惠及所有人”(OpenAI, sama)。Epoch AI 的另一条说明给出规模参照:该轮融资几乎将 OpenAI 历史累计融资拉升至三倍;The Information 据称预计其到 2028 年累计现金消耗达 1570亿美元,而本轮资金加现有现金大致与该预测匹配(EpochAIResearch)。
-
Deployment Safety Hub:OpenAI 上线可检索站点,用于浏览“system cards”(此前多为 PDF),让部署安全文档更易访问(dgrobinson)。
美国国防部(“战争部”)与 Anthropic 争议:供应链定性、反弹与行业影响
-
Anthropic 划出红线,科技圈强烈回应:争议焦点在于 Anthropic 公开拒绝支持大规模国内监控和全自主武器(按转述者对声明的解读),由此获得罕见的跨竞争对手赞许,也让前沿模型部署中的“红线”议题进一步升温(mmitchell_ai, ilyasut)。
-
“定性冲击”与法律边界争论:社交平台流传“战争部”拟将 Anthropic 定性为**‘国家安全供应链风险’并向承包商/合作方施压,引发对合法性、先例与寒蝉效应的争辩(kimmonismus, deanwball)。一项法律澄清认为:DoD 可以限制承包商在DoD 合同工作**中的行为,但很可能无权禁止其在私人/商业业务中使用 Anthropic(petereharrell)。
-
经济与战略后果框架:最严厉的批评称,此举将损害美国作为商业伙伴的信誉,并可能迫使 hyperscaler 与投资方面临不可调和的抉择(deanwball);也有人表示在完整细节未明前仍需观望,但依旧认为“供应链风险”定性并不贴切(jachiam0)。
-
公众情绪显著升温:多条帖子强调公众对“DoD 支持国内监控计划并惩罚拒绝者”的强烈愤怒(quantian1, janleike)。不少用户表示会“用订阅支持”Claude(willdepue, Yuchenj_UW)。
-
Anthropic 官方回应与诉讼意向:Anthropic 发布正式声明回应 Hegseth 部长相关表态(AnthropicAI)。评论特别关注“将在法庭上挑战任何供应链风险定性”这句话,并强调争议核心之一是:DoD 合同范围外客户是否应被限制(iScienceLuvr)。
-
更高层面的议题:无论立场如何,许多观点都将此视作一次治理先例时刻:谁来决定可接受用途、程序正义如何保障、合同体系如何应对模型能力快速迭代(kipperrii)。
模型与榜单:Qwen3.5 扩展与“开源模型”排名
-
Qwen3.5 新发布(Artificial Analysis 汇总):阿里巴巴扩展 Qwen3.5 系列,新增 27B dense、122B A10B MoE、35B A3B MoE,均为 Apache 2.0,262K context(帖子称可通过 YaRN 扩展至 1M)。Artificial Analysis 给出的 Intelligence Index 分数为:27B = 42、122B A10B = 42、35B A3B = 37,并列出 agent/task 指标(如 27B 的 GDPval-AA 1205)及权衡细节(幻觉率/准确率、token 消耗——27B 跑完整个指数用了 9800万输出 token)(ArtificialAnlys)。
-
Arena 榜单(2026年2月):Arena 发布文本与代码的 Top Open Models。文本榜前三:GLM-5 (1455)、Qwen-3.5 397B A17B (1454)、Kimi-K2.5 Thinking (1452)(arena)。Code Arena 榜首为 GLM-5 (1451),Kimi-K2.5 与 MiniMax-M2.5 并列第二(arena)。Arena 同时强调其开源可复现榜单工具包 Arena-Rank(arena)。
-
Perplexity 开源双向 embedding 模型(未获一手发布佐证):有帖子称 Perplexity 开源了双向“Qwen3-retrained” embedding 模型(0.6B/4B;标准版与上下文感知版;MIT 许可),用于提升检索中的文档级理解;该信息应视为第三方总结而非官方首发说明(LiorOnAI)。
系统、推理、内核与 RL 训练:带宽、ROCm 与离策略 RL
- vLLM 在 ROCm 上的 attention 后端(AMD):vLLM 宣布为 ROCm 提供 7 种 attention backend,配合 KV-cache 布局调整、批处理技巧与模型特化内核;据称在 AMD GPU 上 decode 吞吐最高提升 4.4×,可通过环境变量切换(
VLLM_ROCM_USE_AITER=1)(vllm_project)。后续还披露 MLA KV 压缩相关数据(例如 ~8K → 576 维)以及在 MI300X/MI32 上的吞吐提升。
[... content truncated ...]
原文链接:https://www.latent.space/p/ainews-openai-closes-110b-raise-from