[AINews] Anthropic 指控 DeepSeek、Moonshot 与 MiniMax 发起超 1600 万次“工业级蒸馏攻击”
![[AINews] Anthropic 指控 DeepSeek、Moonshot 与 MiniMax 发起超 1600 万次“工业级蒸馏攻击”](https://substackcdn.com/image/fetch/$s_!mjWq!,w_1200,h_675,c_fill,f_jpg,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F8f0e994e-d0fa-4728-9d61-34c0df21d7a0_1376x768.jpeg)
Title: [AINews] Anthropic 指控 DeepSeek、Moonshot 和 MiniMax 发起超 1600 万次“工业级蒸馏攻击”
Summary: 中美冷战在 AI 领域明显升级
Content: 今天是个“大事套小事”的一天:SWE-Bench Verified 已死,SaaS/DoorDash 股票明显下跌,围绕 Citrini 2028 文章 也出现了大量拉扯讨论;但我们会像对待 AI 2027 一样,先把这类“末日科幻”放一边——不是它一定不会发生,而是它无法被验证。
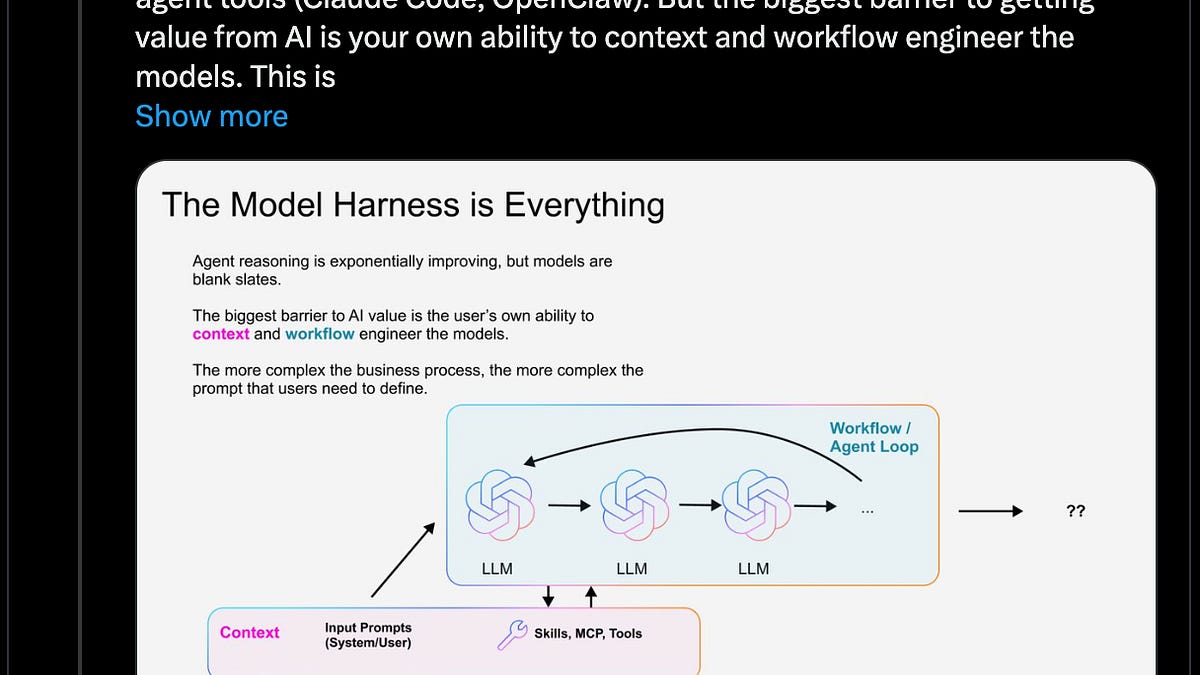
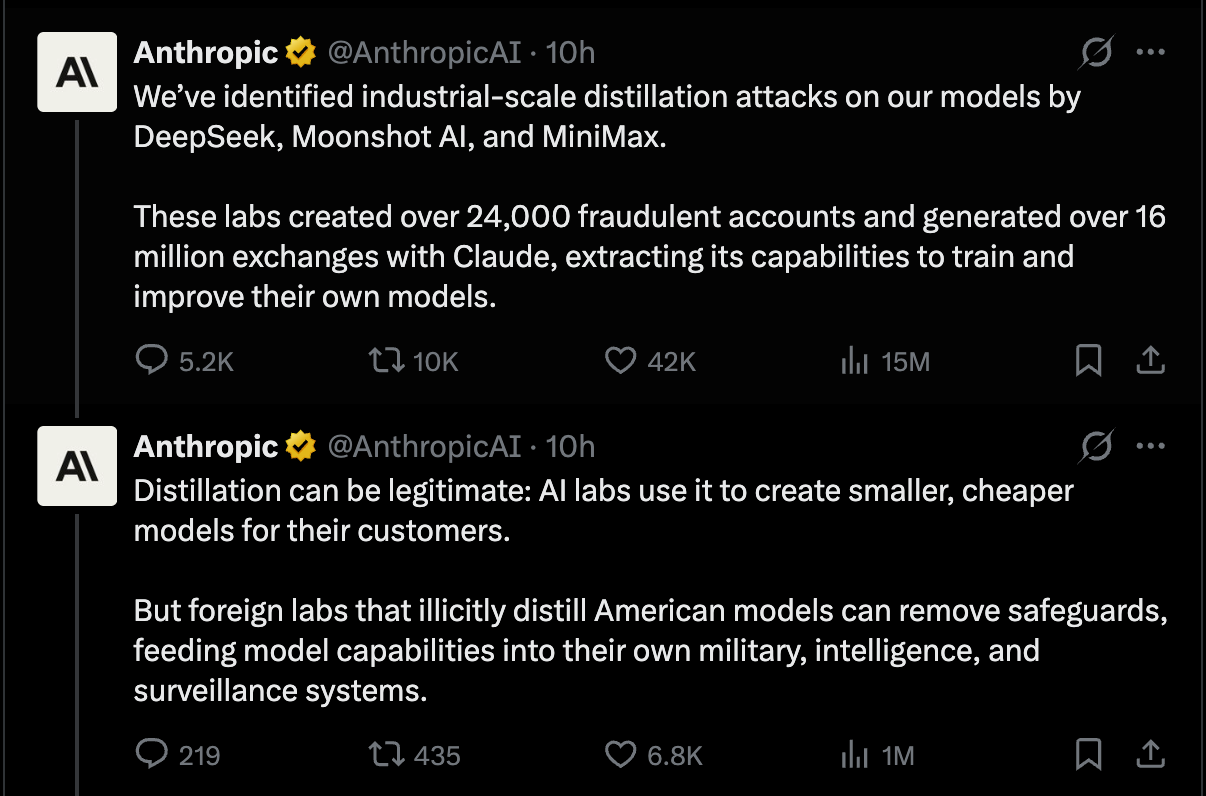
当下更可信、也更具现实冲击力的,是 Anthropic 这条观看量极高、同时争议巨大的指控:其称三家中国头部实验室存在蒸馏行为。
[
这些“蒸馏”规模差异很大——MiniMax 比 Moonshot 高一个数量级,Moonshot 又比 DeepSeek 高一个数量级:
[
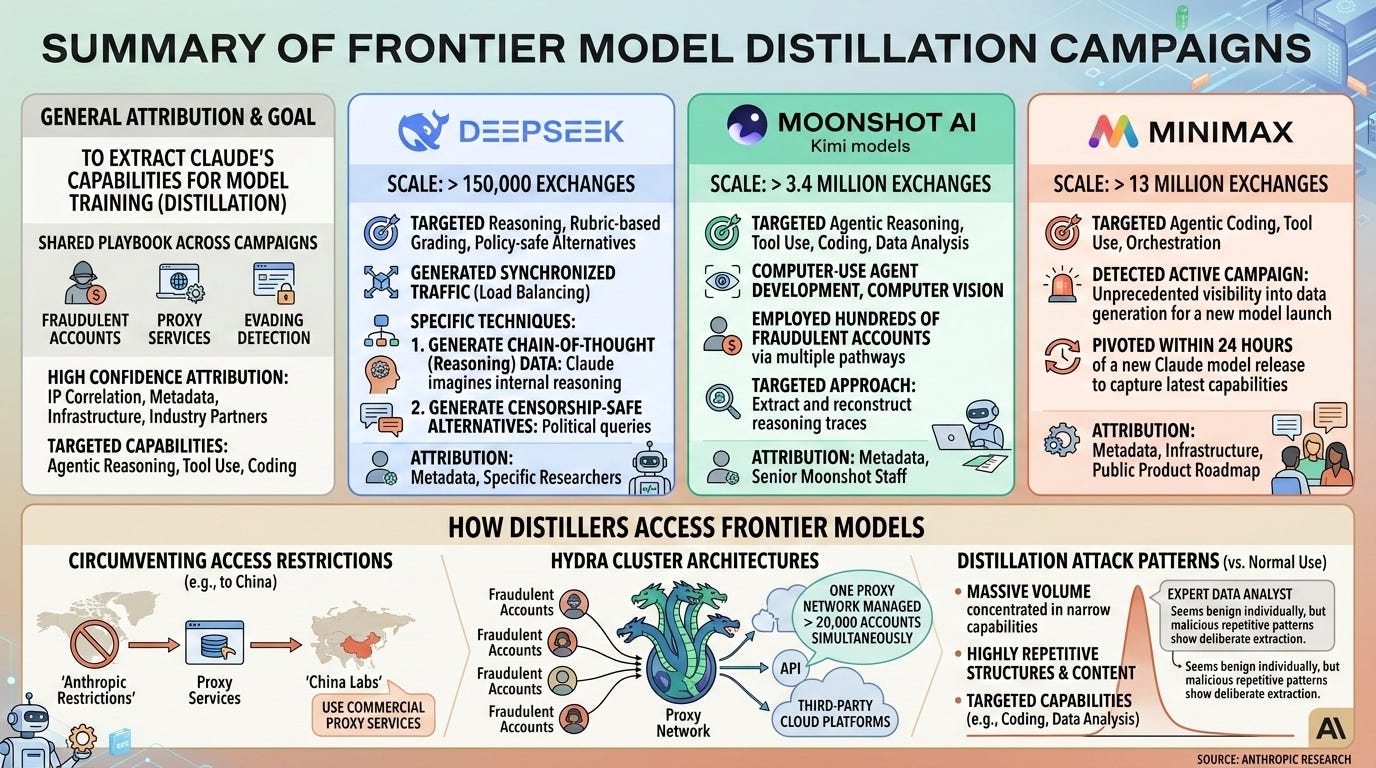
不过,时间点同样关键——Anthropic 还称其在 MiniMax 正在进行中的一次蒸馏任务中“抓了现行”,推测与 M2.5 有关;但相较于 DeepSeek(推测主要在 V3 与 R1 时期完成,且规模更小),进行中的任务本来就更容易被发现。(又或者……他们更会隐藏?)
值得一提的是,Qwen 与 Z.ai(GLM)并未被点名。截至目前,被指控公司均未公开回应。
Anthropic 并非孤例——OpenAI 去年和近期也提出过类似、但更低调的抱怨。
[

Shirin Ghaffary@shiringhaffary
](https://x.com/shiringhaffary/status/2022071345685967111)
10:12 PM · Feb 12, 2026 · 227K Views
44 Replies · 33 Reposts · 265 Likes
这条新闻出现的时点也耐人寻味:一方面 Dario 正呼吁对华更严格的出口管制,另一方面 DeepSeek V4 发布在即,且“中文开源模型正在追平西方闭源模型”的观点也在持续发酵。
Anthropic 关于 Claude“蒸馏攻击”的指控(以及行业反噬)
-
Anthropic 的说法:Anthropic 表示其检测到 DeepSeek、Moonshot AI、MiniMax 对 Claude 发起了_工业级_蒸馏:约 24,000 个欺诈账号产生了 >16M 次 Claude 交互,据称目的是为其自有模型抽取能力(Anthropic, follow-up, blog link tweet)。Anthropic 将风险定义为竞争层面(能力迁移)与安全/地缘政治层面(绕开安全护栏、下游军情用途)双重风险。
-
社区反应 /“双标”讨论:大量回复将其解读为“实验室先用互联网数据训练,如今却反对被复制”,并常把抓取网页与 API 输出抽取对比讨论(Elon, ThePrimeagen, Teknium, Suhail, HKydlicek)。另一派则认为,这种规模的蒸馏本质不同,因为它可能复制_工具使用 / Agent 行为_,并潜在绕过安全控制(RundownAI summary, LiorOnAI take)。
-
二阶影响:讨论折射出安全模型正在迁移:前沿模型的防护不再只靠权重保密和算力稀缺,也越来越依赖 API 滥用防护能力(账号欺诈识别、绕限速检测、行为指纹、水印等)。这也再次抛出问题:如果能力可通过大规模输出“复制”,那么 出口管制还能否有效(LiorOnAI)。
-
相关市场/时间背景:有人将公告时点与即将到来的 DeepSeek V4 新闻周期联系起来(kimmonismus),并置于更广泛的中美叙事中解读。
Coding Agent:真实落地、真实失败与“Agentic Engineering”方法论
-
Codex + Claude Code 热度上行(meme 背后是工作流重构):高互动帖子里,大量是“Agent 已经来了”的实战轶事,例如周末用 Codex 搭产品(OpenAIDevs, gdb),也有关于给 Agent 过高权限的失败案例。该批案例中的经典故障模式是:指令丢失/压缩导致误执行破坏性操作(如删邮件),常见于 OpenClaw 式系统(summeryue0, follow-up root-cause,以及围绕“写权限风险”的讨论:Yuchenj_UW)。
-
Agentic Engineering 指南正在收敛:
-
Simon Willison 发布了 《Agentic Engineering Patterns》 的首批章节,面向 Claude Code/Codex 等 coding agents(simonw)。
-
一个小争议是“删掉你的 CLAUDE.md/AGENTS.md”(即:过度定制可能只是形式主义)(theo,呼应者 bpodgursky,以及“硬修剪”式回应 ryancarson)。
-
-
OpenClaw 生态扩张 + 替代方案:
-
NanoClaw 定位为更小型、容器隔离的 OpenClaw 类助手,支持 WhatsApp I/O、swarm、定时任务等(TheTuringPost, repo: qwibitai/nanoclaw)。
-
多套“如何构建 OpenClaw 式 Agent”方案强调了无聊但关键的基础件:调度/队列、sandbox、实时通信(TheTuringPost stack list)。
-
Ollama 0.17 让 open models 与 OpenClaw 的组合更简单,也显示“本地 Agent 执行 = 安全诉求”仍在增强(ollama)。
-
-
企业级/生产级 Agent 工程重心转向可观测性与评测闭环:Exa 的“deep research agent”案例强调 token/caching 可观测性就是定价基础设施(LangSmith/LangGraph)(LangChain)。monday.com 的服务 Agent 将 eval 设为“Day 0”能力,并称借助 LangSmith 实现 8.7× 更快反馈闭环(hwchase17)。
基准与评测完整性:SWE-Bench Verified 退场、新榜单上线,以及 Agent 生成仓库的瓶颈
-
SWE-Bench Verified 被 OpenAI DevRel 自愿弃用:OpenAI 推荐 SWE-bench Pro,并称 Verified 已经饱和/失真:污染与测试设计缺陷使其无法再衡量前沿 coding 能力(OpenAIDevs, analysis discussion: latentspacepod, recap: swyx, independent summary: rasbt, tl;dr: polynoamial)。推文中反复提到的分析细节是:在审计一批高失败率任务后,发现相当比例存在测试缺陷(会拒绝正确解)和/或任务本身“按题意不可解”。
-
评测开始转向“每美元能力”:AlgoTune 明确设定 每题 1 美元预算,因此榜单可能更偏向低成本模型,把“最好”重定义为 成本约束下的最优(OfirPress)。
-
长程 coding agent 仍明显失灵:NL2Repo-Bench 测试 Agent 能否从零生成可安装的完整 Python 库;据称头部模型通过率仍 低于 40%,主要失败在规划与全仓一致性(jiqizhixin)。
-
OCR 评测现实检验:即便强 OCR 模型,在高密度历史报纸场景也会“崩溃”(幻觉/循环),凸显其在精选数据分布外的脆弱性(vanstriendaniel)。另有 OlmOCR-Bench 作为 HF 基准数据集开放社区提交评测(mervenoyann)。
推理与系统:Agent 的 WebSockets、超高速片上推理,以及基础设施扩容叙事
-
OpenAI Responses API 增加 WebSockets,面向低延迟、长任务、工具密集型 Agent。其逻辑是:持久连接 + 内存态使输入可增量传输,而非反复发送全量上下文;在 20+ 工具调用场景中宣称可提速 20–40%(OpenAIDevs, detail: OpenAIDevs, adoption: OpenAIDevs)。Cline 的早期数据:简单任务约快 15%,复杂工作流约快 39%,最佳可达 50%(cline)。Steven Heidel 则把 Codex 的提速归因于 WebSockets(stevenheidel)。
-
推理工程成为“独立学科”:Baseten 发布 Inference Engineering 书籍(philipkiely),多位工程师强调推理层正在成为延迟/成本/可靠性的竞争主战场(hasantoxr, JayminSOfficial)。
-
硬件/架构信号:
-
有演示声称在 Llama 3.1 8B 上实现 18,000 tokens/sec,方式是“将模型参数蚀刻进晶体管”(计算+存储融合)(philschmid)。
-
NVIDIA 发布面向 Blackwell 优化的 Qwen3.5 MoE,量化为 NVFP4,并称使用 SGLang 可实现 2× 推理加速(HuggingPapers)。
-
fal 分享其推理引擎中的通信/计算重叠优化(“Async Ulysses”)(isidentical)。
-
-
算力战略叙事冲突:关于 OpenAI “Stargate” 数据中心项目停滞的说法,在讨论串中被另一种框架反驳:Stargate 是多方算力生态的伞形品牌(SoftBank/NVIDIA/AMD/Broadcom/Oracle/Microsoft/AWS/CoreWeave/Cerebras),且 2025 年底可用算力约 2GW(kimmonismus claim vs sk7037 response)。
模型/榜单更新与研究线索(推理、记忆、多模态视频)
-
Arena 榜单:GPT-5.2-chat-latest 以 1478 进入 Text Arena 前 5,较 GPT-5.2 提升 +40;改进点包括多轮对话、指令遵循、困难提示与 coding(arena, breakdown: arena)。
-
Gemini 3.1 Pro:WeirdML 得分 72.1%,高于 3.0 的 69.9%;评价为“高峰值 + 奇怪短板”,且输出 token 消耗明显更高(htihle)。另有不少开发者吐槽容量与 tool-calling 可靠性(theo, theo follow-up, later: theo)。
-
Qwen3.5 发布传闻:有推文称 Qwen 发布 397B 多模态 MoE(17B active),并“对标 GPT5.2/Claude 4.5”(HuggingPapers)。在查看 model card/evals 前,应谨慎看待该对比。
-
推理训练 / CoT:
-
Teknium 认为 verifier 不是“免费午餐”:更强 solver 往往也是更强 verifier;用更小、更“笨”的 judge 去判难题通常会失效(Teknium)。
-
ByteDance 风格 CoT 工程被描述为:从长度惩罚转向“强制压缩”流水线;并提出长 CoT 的“分子结构”视角(语义同分异构体)与合成数据方法(Mole-Syn)(teortaxesTex, summary via TheTuringPost)。
-
DAIR 强调一篇关于 CoT 可监控性 的信息论论文(互信息是必要非充分条件;监控抽取与诱导误差会带来缺口),并提出提升透明性的训练方法(dair_ai)。
-
-
视频 / 世界模拟:多篇关于交互式视频生成和多镜头生成的论文密集发布(akhaliq interactive video, akhaliq multishot, QingheX42 code release);产品侧还有 Kling 3.0 接入 Runway 工作流([runwayml](https://x.com/runwayml/status
[... content truncated ...]
原文链接:https://www.latent.space/p/ainews-anthropic-accuses-deepseek