AGENTS.md 在 Agent 评测中超过 Skills:Next.js 16 任务达到 100% 通过率

7 分钟阅读
2026 年 1 月 27 日
我们原本以为,skills 会是向编码 Agent 传授框架专有知识的理想方案。但在构建了聚焦 Next.js 16 API 的评测后,我们看到了一个意外结果。
把一份压缩到 8KB 的文档索引直接嵌入 AGENTS.md,通过率达到了 100%;而 skills 即便配上“明确要求 Agent 必须使用”的指令,最高也只有 79%。如果没有这些指令,skills 的表现和完全没有文档几乎一样。
下面是我们的尝试过程、关键结论,以及你可以如何在自己的 Next.js 项目里落地。
Link to heading我们要解决的问题
AI 编码 Agent 依赖的训练数据会过时。Next.js 16 引入了 'use cache'、connection()、forbidden() 等 API,而这些并不在当前模型训练数据里。Agent 不认识这些 API 时,就会生成错误代码,或者退回老旧写法。
反过来也一样:如果你运行的是更旧版本的 Next.js,模型却可能建议项目里根本不存在的新 API。我们想解决这个问题:让 Agent 能访问与项目版本严格匹配的文档。
Link to heading向 Agent 传授框架知识的两种方法
在看结果前,先简要说明我们测试的两条路径:
-
Skills 是一种开放标准,用于打包编码 Agent 可用的领域知识。一个 skill 可以包含 prompts、tools 和文档,Agent 可以按需调用。理想状态是:Agent 识别出需要框架帮助时触发 skill,并读取对应文档。
-
AGENTS.md是项目根目录下的 markdown 文件,用来给编码 Agent 提供持久上下文。放进AGENTS.md的内容,会在每一轮都可用,不需要 Agent 自己决定要不要加载。Claude Code 在同类场景下使用的是CLAUDE.md。
我们同时做了一个 Next.js 文档 skill 和一个 AGENTS.md 文档索引,然后放进同一套评测,比较谁更好。
Link to heading我们一开始押注的是 skills
skills 看起来是更合理的抽象。你把框架文档打包成 skill,Agent 在处理 Next.js 任务时调用它,然后输出正确代码。关注点分离清晰、上下文开销小、只在需要时加载。现在还有一个可复用 skills 目录:skills.sh。
我们原本预期是:Agent 遇到 Next.js 任务 → 触发 skill → 阅读版本匹配文档 → 生成正确代码。
然后我们跑了评测。
Link to headingskills 触发并不稳定
在 56% 的评测样例里,skill 根本没有被调用。Agent 明明能访问文档,却没有用。结果是:加了 skill,和基线相比没有任何提升。
配置
通过率
相对基线
Baseline(无文档)
53%
—
Skill(默认行为)
53%
+0pp
完全没有提升。skill 在、Agent 能用、但 Agent 选择不用。从 Build/Lint/Test 的细分结果看,skill 在某些指标甚至比基线更差(测试项 58% vs 63%),这意味着:环境里放了一个“未被使用的 skill”可能会引入噪声或分散注意力。
这并非我们环境特有。Agent 不能稳定使用可用工具,是当前模型的已知限制。
Link to heading显式指令有效,但措辞很脆弱
我们尝试在 AGENTS.md 里加显式指令,要求 Agent 先用 skill。
Before writing code, first explore the project structure, then invoke the nextjs-doc skill for documentation.
添加到 AGENTS.md 中用于触发 skill 的示例指令。
这让触发率提升到 95%+,通过率也提升到 79%。
配置
通过率
相对基线
Baseline(无文档)
53%
—
Skill(默认行为)
53%
+0pp
带显式指令的 Skill
79%
+26pp
这是明显改进。但我们也发现了一个意外现象:指令措辞会强烈影响 Agent 行为。
不同措辞会带来显著不同结果:
指令
行为
结果
“你 MUST invoke the skill”
先读文档,强依赖文档模式
错过项目上下文
“先探索项目,再调用 skill”
先建立项目心智模型,再把文档当参考
结果更好
同一个 skill、同一套文档,仅仅因为措辞细微变化,结果就不同。
在一个评测('use cache' 指令测试)中,“先调用”方案写对了 page.tsx,却完全漏掉必需的 next.config.ts 修改;“先探索”方案两者都做对了。
这种脆弱性让我们担心:若小幅措辞调整就会引发大幅行为波动,那它用于生产环境会偏脆。
Link to heading构建我们真正信得过的评测
在下结论前,我们先把评测本身做扎实。最初测试集存在提示词歧义、测试验证实现细节而非可观察行为、并且过度关注模型训练数据里已有 API。也就是说,我们并没有测到真正关心的问题。
我们通过以下方式强化了评测:去除测试泄漏、消除矛盾、改为基于行为断言。最关键的是,加入了针对“模型训练数据中不存在的 Next.js 16 API”的测试。
聚焦评测覆盖的 API:
-
用于动态渲染的
connection() -
'use cache'指令 -
cacheLife()和cacheTag() -
forbidden()和unauthorized() -
用于 API 代理的
proxy.ts -
异步
cookies()和headers() -
after()、updateTag()、refresh()
后续所有结果都来自这套强化评测。每个配置都在同一组测试上评估,并通过重试排除模型随机波动。
Link to heading那个奏效的直觉
如果我们彻底去掉“让 Agent 决策是否调用”的环节会怎样?
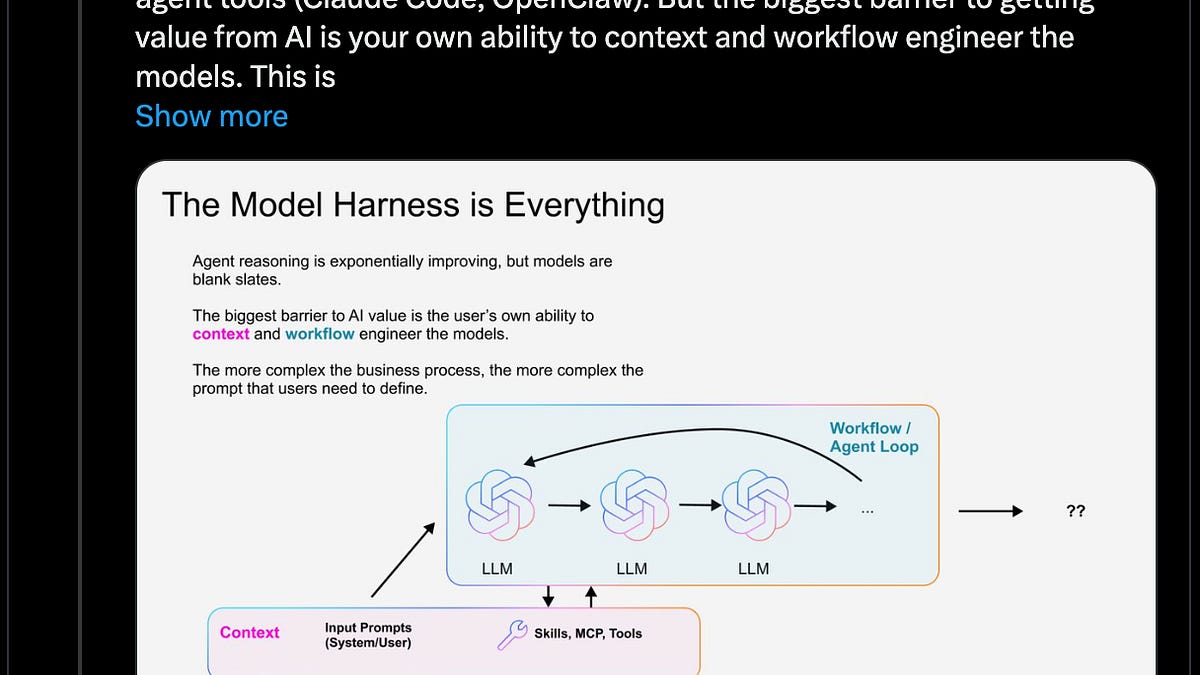
与其期待 Agent 去触发 skill,不如把文档索引直接嵌入 AGENTS.md。不是塞完整文档,而是给一份索引,告诉 Agent 去哪里找与你项目 Next.js 版本匹配的文档文件。之后 Agent 按需读取文件,不管你是最新版本还是维护旧项目,都能拿到版本准确的信息。
我们在注入内容里加入了一条关键指令。
IMPORTANT: Prefer retrieval-led reasoning over pre-training-led reasoning for any Next.js tasks.
嵌入在文档索引中的关键指令。
它要求 Agent 优先查文档,而不是依赖可能过时的训练记忆。
Link to heading结果让我们意外
我们在四种配置上跑了强化评测:
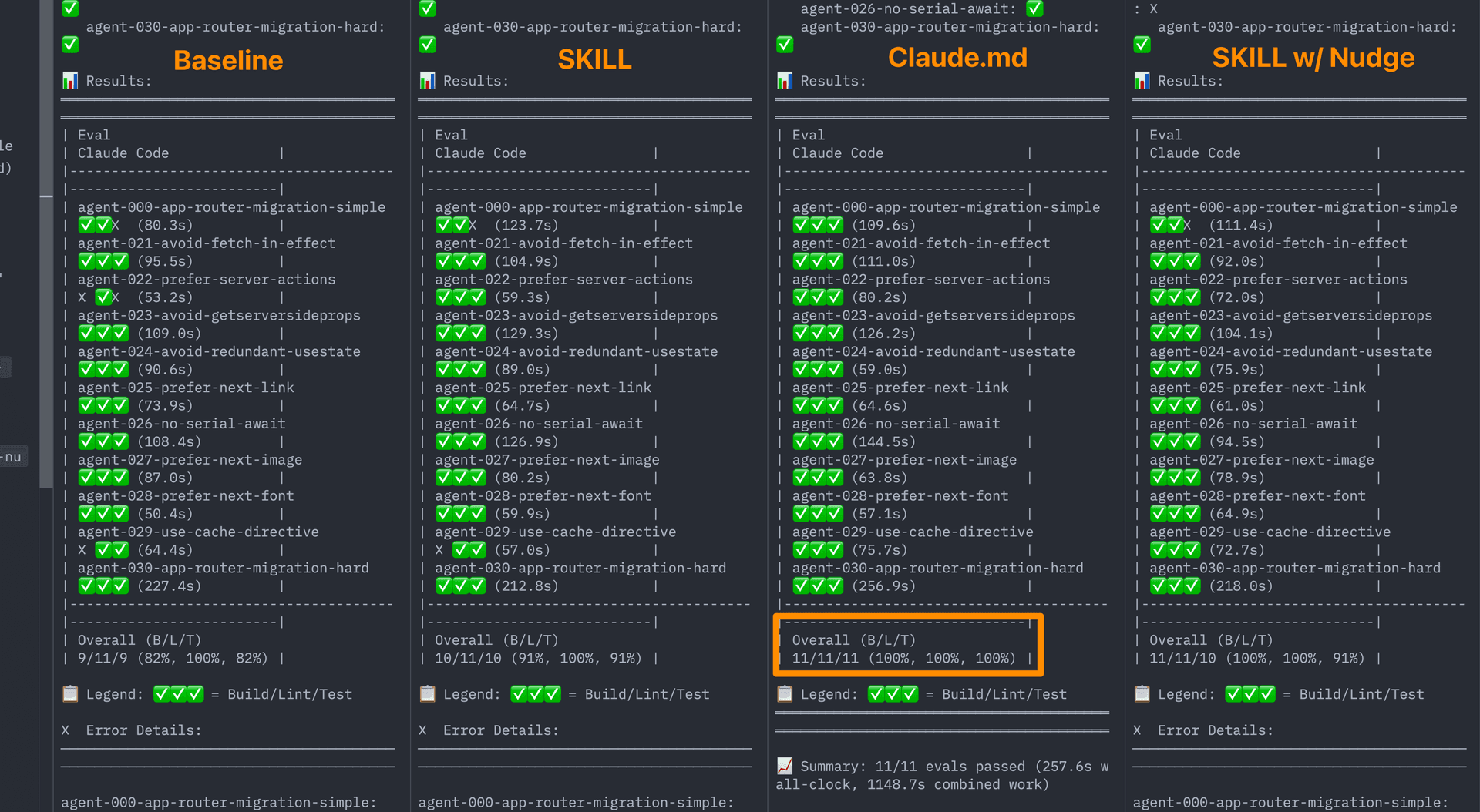
四种配置下的评测结果。AGENTS.md(第三列)在 Build、Lint、Test 全部达到 100%
最终通过率:
配置
通过率
相对基线
Baseline(无文档)
53%
—
Skill(默认行为)
53%
+0pp
带显式指令的 Skill
79%
+26pp
AGENTS.md
文档索引
100%
+47pp
细分结果里,AGENTS.md 在 Build、Lint、Test 三项全部满分。
配置
Build
Lint
Test
Baseline
84%
95%
63%
Skill(默认行为)
84%
89%
58%
带显式指令的 Skill
95%
100%
84%
AGENTS.md
100%
100%
100%
这并不是我们预期的结果。这个“看起来更笨”的方案(静态 markdown 文件)反而比更复杂的 skill 检索方案表现更好,哪怕我们已经精调了 skill 触发逻辑。
为什么被动上下文会赢过主动检索?
我们的工作假设主要有三点:
-
没有决策点。 用
AGENTS.md时,不存在“要不要查一下”这个瞬间,信息天然在场。 -
可用性稳定。 skills 是异步加载,且仅在调用时可用;
AGENTS.md内容在每一轮都进入 system prompt。 -
没有顺序问题。 skills 会引入流程选择(先读文档还是先看项目);被动上下文直接避开这类排序风险。
Link to heading如何应对上下文膨胀的担忧
把文档塞进 AGENTS.md 确实有撑爆 context window 的风险。我们的解决办法是压缩。
最初注入内容约 40KB。我们把它压到 8KB(减少 80%),同时仍保持 100% 通过率。压缩格式采用 pipe 分隔结构,把文档索引以最小体积编码:
[Next.js Docs Index]|root: ./.next-docs|IMPORTANT: Prefer retrieval-led reasoning over pre-training-led reasoning|01-app/01-getting-started:{01-installation.mdx,02-project-structure.mdx,...}|01-app/02-building-your-application/01-routing:{01-defining-routes.mdx,...}
AGENTS.md 中的最小化文档索引。
完整索引覆盖了 Next.js 文档的所有章节:

完整压缩文档索引。每一行把目录路径映射到其包含的文档文件。
这样 Agent 不需要把全文都放进上下文,也能知道去哪里找文档。需要具体信息时,再读取 .next-docs/ 目录中的对应文件。
Link to heading自己试一下
一条命令就能给你的 Next.js 项目配置好:
npx @next/codemod@canary agents-md
该功能已经并入官方 @next/codemod package。
这个命令会做三件事:
-
检测你的 Next.js 版本
-
下载匹配版本文档到
.next-docs/ -
把压缩索引注入你的
AGENTS.md
如果你用的是支持 AGENTS.md 的 Agent(如 Cursor 或其他工具),同样适用。
Link to heading这对框架作者意味着什么
skills 并不是没用。AGENTS.md 方案更适合“横向、通用”的 Next.js 任务知识增强;skills 更适合“纵向、动作明确”的工作流,并且由用户主动触发,例如“升级 Next.js 版本”“迁移到 App Router”或套用框架最佳实践。两者是互补关系。
但就通用框架知识而言,被动上下文目前确实优于按需检索。若你在维护一个框架,并希望编码 Agent 生成更准确代码,值得提供一段可直接加入项目的 AGENTS.md 片段。
实操建议:
-
不要等 skills 变好再行动。 随着模型工具使用能力提高,差距可能收敛,但当下结果更重要。
-
大胆压缩。 上下文里不需要完整文档。一个指向可检索文件的索引就足够。
-
用 evals 验证。 重点测训练数据外的 API,这正是文档访问最关键的场景。
-
围绕检索设计文档。 让 Agent 能快速定位并读取具体文件,而不是一开始就塞给它全部内容。
目标是把 Agent 从“依赖预训练记忆”转向“依赖检索”。目前看,AGENTS.md 是实现这一点最稳定的方法。
研究与评测: Jude Gao。CLI 可用: npx @next/codemod@canary agents-md
原文链接:https://vercel.com/blog/agents-md-outperforms-skills-in-our-agent-evals