用 fetch() HTTP Range 请求做二分搜索的 Unicode Explorer
27th February 2026 - Link Blog
[用 fetch() HTTP Range 请求做二分搜索的 Unicode Explorer](https://tools.simonwillison.net/unicode-binary-search)。这是我今天早上用手机做的一个小原型,一方面是对 HTTP Range 请求的实验,另一方面也算是一个“用 LLM 满足好奇心”的通用示例。
我已经收集 [HTTP Range 技巧](https://simonwillison.net/tags/http-range-requests/) 有一段时间了,于是决定自己做点有意思的东西:对一个大文件进行二分搜索,完成一件真正有用的事。
所以我先 [和 Claude 做了头脑风暴](https://claude.ai/share/47860666-cb20-44b5-8cdb-d0ebe363384f)。难点在于找到一个适合二分搜索的用例——数据要能天然排序,这样二分法才能发挥优势。
Claude 的一个建议是:查询 unicode codepoints 的信息,这意味着要在数十 MB 的元数据里搜索。
我让 Claude 写了一份规范给 Claude Code——[在这里可以看到](https://github.com/simonw/research/pull/90#issue-4001466642)——然后在我的 [simonw/research](https://github.com/simonw/research) 仓库上,用 Claude Code for web 发起了一个[异步研究项目](https://simonwillison.net/2025/Nov/6/async-code-research/),把这份规范变成可运行代码。
这是最终产出的[报告和代码](https://github.com/simonw/research/tree/main/unicode-explorer-binary-search#readme)。我学到的一点很有意思:Range 请求技巧和 HTTP 压缩并不兼容,因为压缩会扰乱字节偏移的计算。我在 fetch() 调用里加了 'Accept-Encoding': 'identity',不过实际上这并非必须,因为 Cloudflare 和其他 CDN 在检测到 content-range header 时会自动跳过压缩。
我把结果部署到了[我的 tools.simonwillison.net 站点](https://tools.simonwillison.net/unicode-binary-search)。在部署前,我先做了调整:通过 Range 请求去查询一个启用了 CORS 的 76.6MB 文件,该文件位于 S3 bucket,并由 Cloudflare 作为前端。
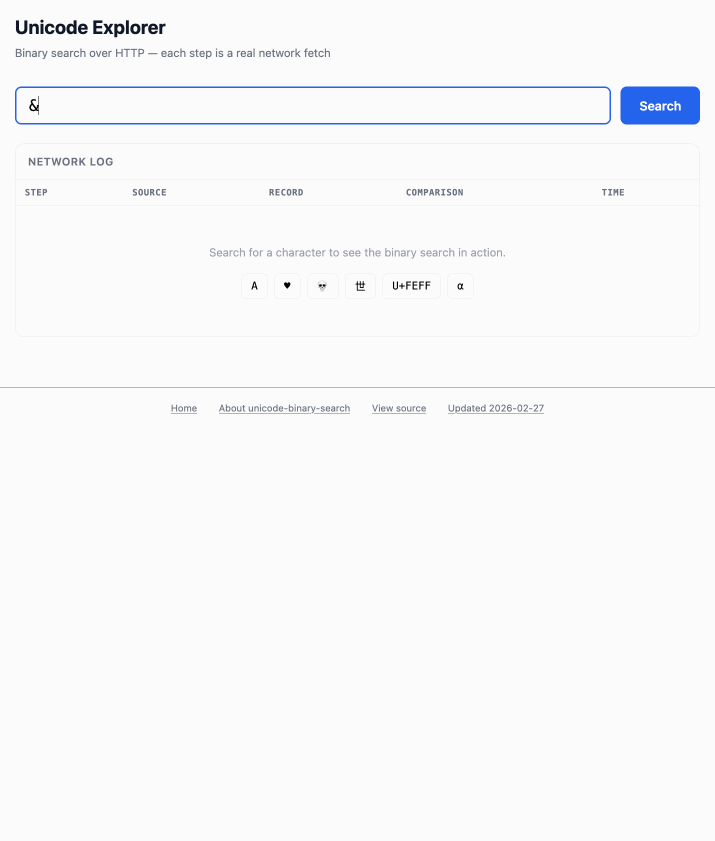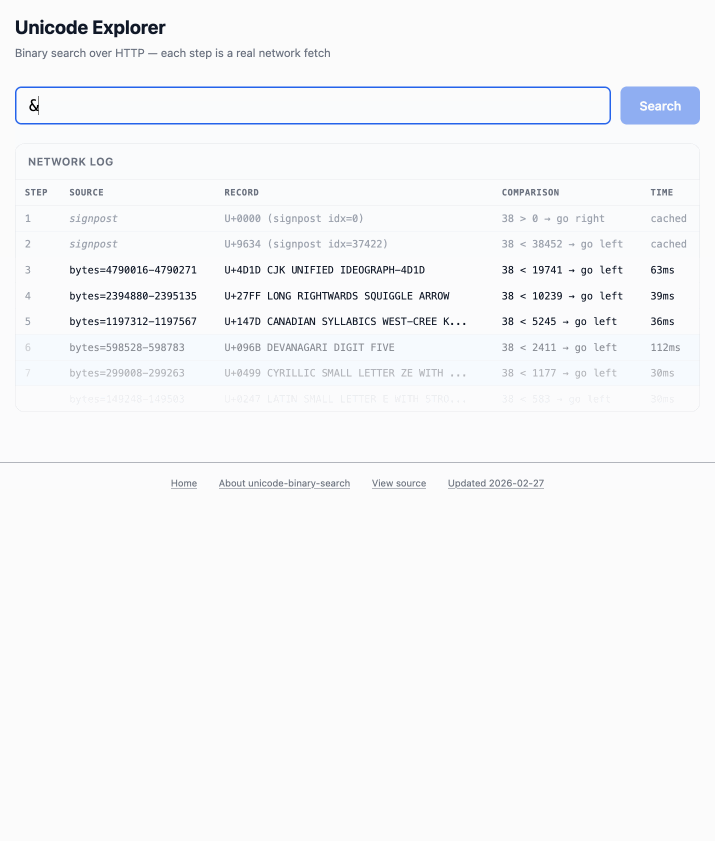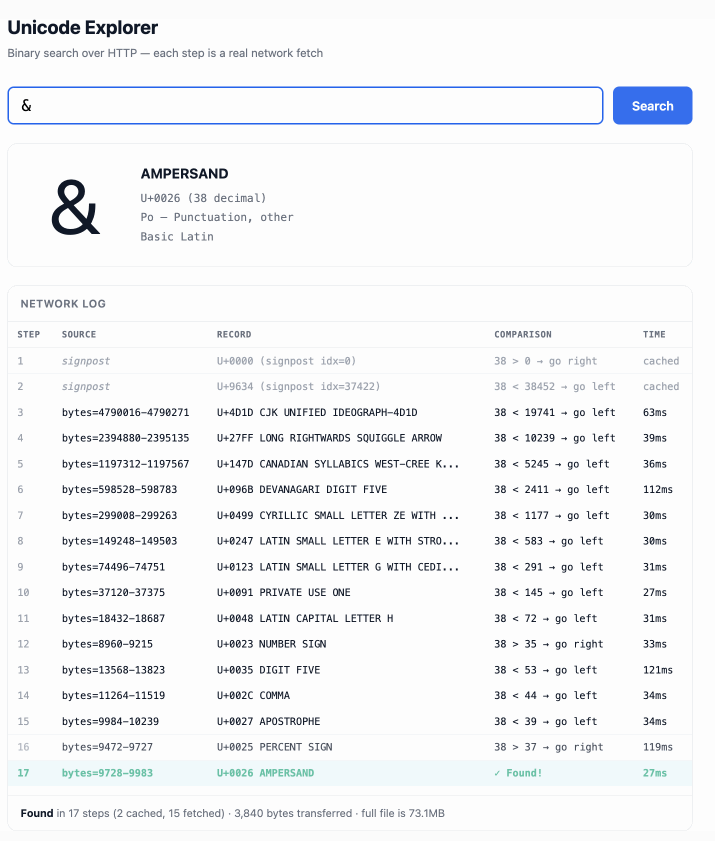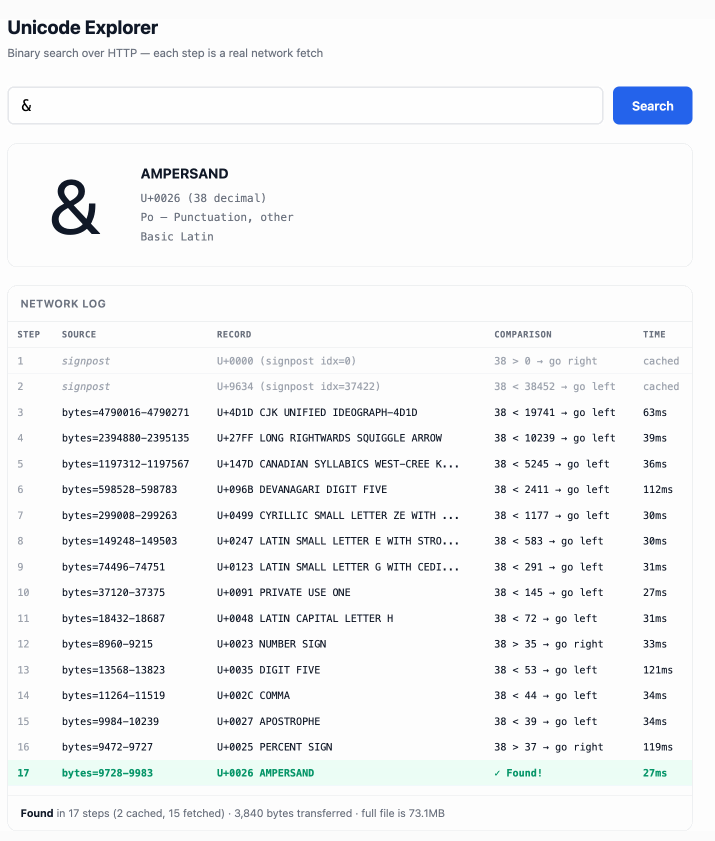
这个 demo 玩起来很有意思——输入单个字符(例如 ø)或十六进制码点标识(例如 1F99C),它就会在大文件中执行二分搜索,并把每一步过程展示出来:
原文链接:https://simonwillison.net/2026/Feb/27/unicode-explorer/#atom-everything
