GitHub Enterprise Server 重构搜索架构:用 CCR 实现高可用升级
So much of what you interact with on GitHub depends on search——这点很直观,比如搜索栏和 GitHub Issues 页面的筛选体验;但它同样是 Releases 页面、Projects 页面、Issues 与 Pull Requests 计数等能力的核心。正因为搜索是 GitHub 平台的关键组成,我们在过去一年里持续提升它的韧性和可靠性。这样一来,你花在 GitHub Enterprise Server 管理上的时间会更少,能把更多精力放在客户最关心的事情上。
过去几年,GitHub Enterprise Server 管理员在处理搜索索引(即为搜索优化的特殊数据库表)时必须格外谨慎。如果维护或升级步骤没有严格按顺序执行,搜索索引可能损坏并需要修复,或者在升级期间被锁定并引发问题。
如果你没有运行 High Availability(HA)部署,这里补充一点背景:HA 的设计目标是在系统部分组件故障时,依然保证 GitHub Enterprise Server 平稳运行。你会有一个负责所有写入和流量的主节点(primary node),以及保持同步、必要时可接管的副本节点(replica nodes)。
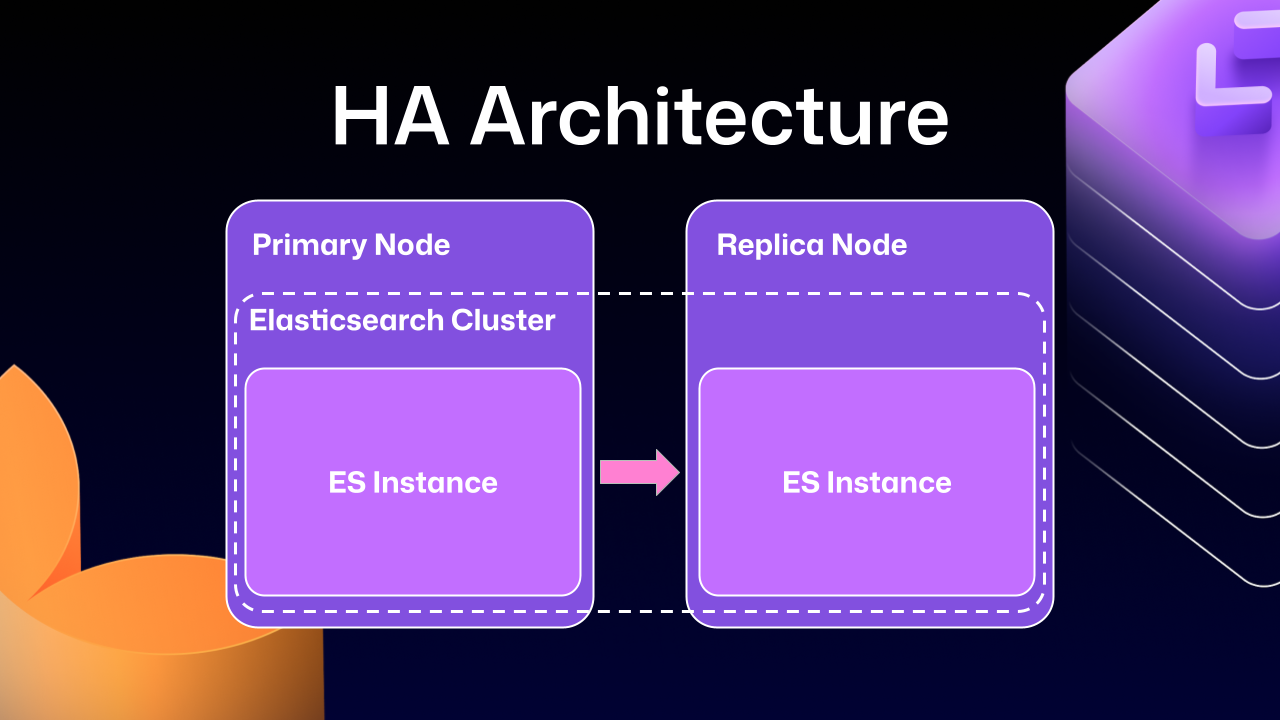
这些难题很大一部分来自早期版本 Elasticsearch(我们选用的搜索数据库)的集成方式。HA 版 GitHub Enterprise Server 采用 leader/follower 模式:leader(主服务器)接收所有写入、更新与流量;followers(副本)设计为只读。这个模式已经深度嵌入 GitHub Enterprise Server 的各项运行机制。
问题在于,Elasticsearch 在这个场景下开始暴露限制。由于它无法直接支持“一个主节点 + 一个副本节点”的模式,GitHub 工程团队当时只能在主节点和副本节点之间组成一个 Elasticsearch cluster。这样做确实让数据复制更直接,同时还带来一些性能收益,因为每个节点都能在本地处理搜索请求。
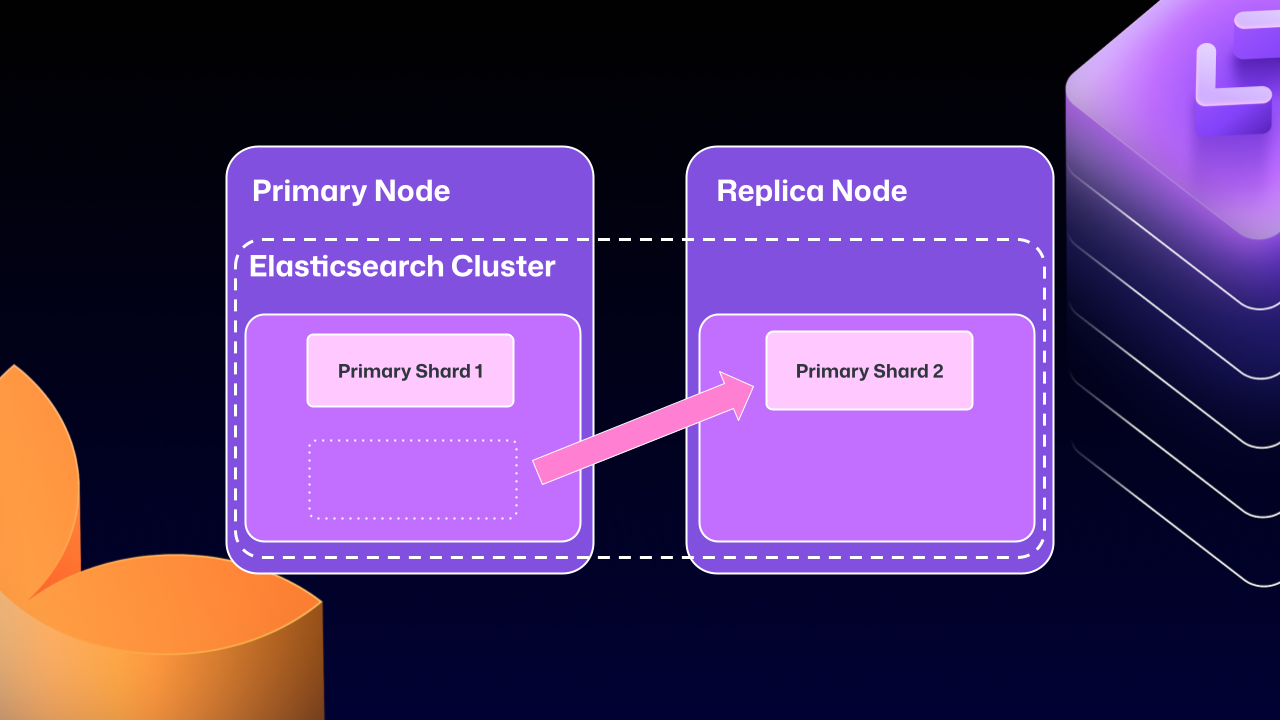
遗憾的是,随着时间推移,这种跨服务器集群的代价开始超过收益。比如,Elasticsearch 可能在任意时刻把一个 primary shard(负责接收/校验写入)迁移到副本节点。如果此时副本节点因维护下线,GitHub Enterprise Server 可能会进入锁死状态:副本要等 Elasticsearch 健康后才能启动,而 Elasticsearch 又要等副本重新加入才会恢复健康。
在多个 GHES 版本周期内,GitHub 工程师一直在尝试提升这种模式的稳定性。我们加入了 Elasticsearch 健康状态检查,也实现了用于纠正状态漂移的流程。我们甚至尝试构建一套“search mirroring”系统,希望摆脱集群模式。但数据库复制本身极具挑战,这些尝试在一致性方面仍面临困难。
有哪些变化?
经过多年工作,我们现在终于可以使用 Elasticsearch 的 Cross Cluster Replication(CCR)功能来支持 HA GitHub Enterprise。
“但是 David,”你可能会说,“这不是集群之间的复制吗?在这里怎么起作用?”
这个问题问得很好。借助这种模式,我们将转向多个“单节点”Elasticsearch cluster。也就是说,每个 Enterprise Server 实例都会作为独立的单节点 Elasticsearch cluster 运行。
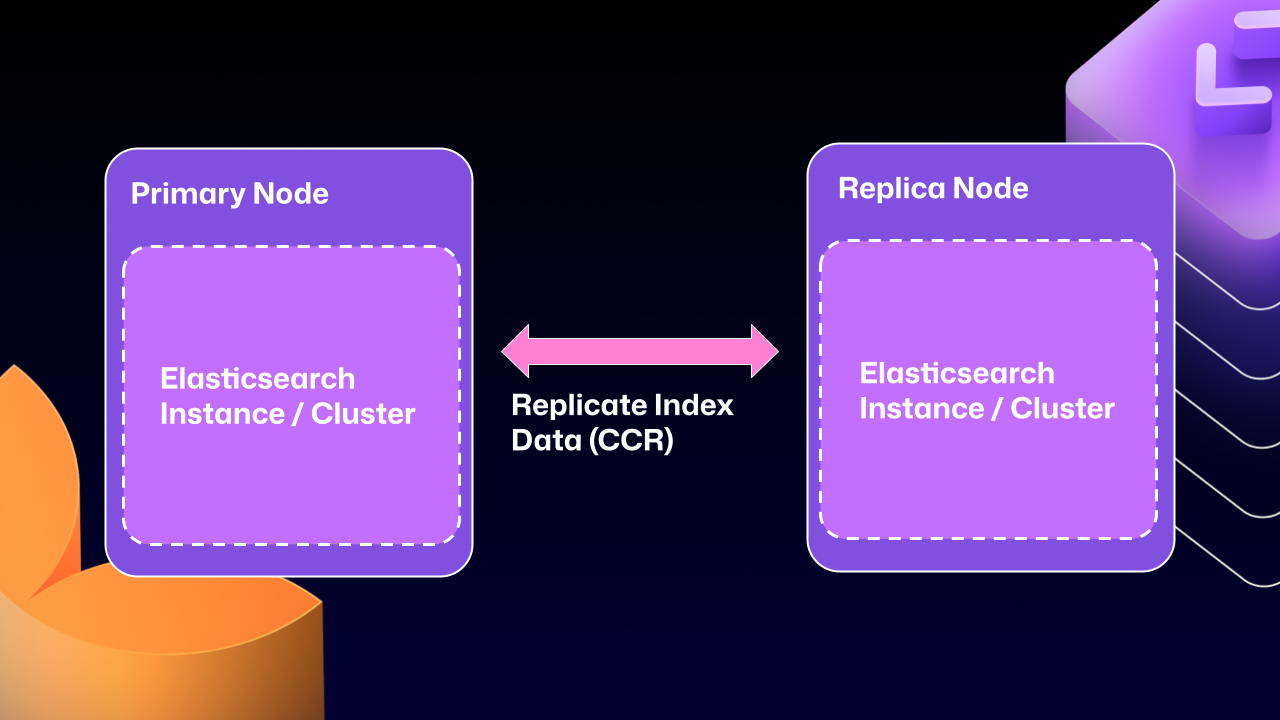
CCR 允许我们以受控、且由 Elasticsearch 原生支持的方式在节点间共享索引数据。它会在数据持久化到 Lucene segment(Elasticsearch 底层数据存储)之后再进行复制。这样可以确保被复制的数据已经在 Elasticsearch cluster 内部被可靠持久化。
换句话说,既然 Elasticsearch 现在支持 leader/follower 模式,GitHub Enterprise Server 管理员将不再面临关键数据落在只读节点上的困境。
底层实现
Elasticsearch 提供 auto-follow API,但它只对策略创建之后新建的索引生效。而 GHES 的 HA 部署通常已有一批长期存在的索引,因此我们需要一个 bootstrap 步骤:先把 followers 挂接到现有索引,再为未来新索引启用 auto-follow。
下面是该流程的示例:
function bootstrap_ccr(primary, replica):
# Fetch the current indexes on each
primary_indexes = list_indexes(primary)
replica_indexes = list_indexes(replica)
# Filter out the system indexes
managed = filter(primary_indexes, is_managed_ghe_index)
# For indexes without follower patterns we need to
# initialize that contract
for index in managed:
if index not in replica_indexes:
ensure_follower_index(replica, leader=primary, index=index)
else:
ensure_following(replica, leader=primary, index=index)
# Finally we will setup auto-follower patterns
# so new indexes are automatically followed
ensure_auto_follow_policy(
replica,
leader=primary,
patterns=[managed_index_patterns],
exclude=[system_index_patterns]
)
这只是我们为在 GHES 中启用 CCR 而构建的新流程之一。我们还为故障切换、索引删除和升级定制了专门的工作流。Elasticsearch 只负责文档复制,索引生命周期的其余部分仍由我们负责。
如何开始使用 CCR 模式
如果你想启用新的 CCR 模式,请联系 support@github.com,并说明希望在 GitHub Enterprise Server 中使用新的 HA 模式。支持团队会为你的组织开通权限,以便下载所需许可证。
下载新许可证后,需要设置 ghe-config app.elasticsearch.ccr true。完成后,管理员可在集群上执行 config-apply 或升级到 3.19.1(首个支持该新架构的版本)。
当 GitHub Enterprise Server 重启后,Elasticsearch 会将现有部署迁移到新的复制方式:把所有数据收敛到主节点、拆除跨节点集群关系,并通过 CCR 重新建立复制。根据 GHES 实例规模不同,这个更新过程可能需要一些时间。
目前这套新 HA 方法仍是可选项,但我们计划在未来两年内将其设为默认。我们希望给 GitHub Enterprise 管理员充足时间反馈意见,因此现在正是试用它的好时机。
我们非常期待你开始使用新的 HA 模式,让 GitHub Enterprise Server 的管理体验更加顺畅。
想在 High Availability 的 GHES 部署中把搜索能力发挥到极致?欢迎 联系支持团队 来启用我们的新搜索架构!
作者

GitHub 软件工程师。David 是搜索工程领域专家,覆盖 GitHub 内从基础设施到相关性工程的信息检索全栈方向。
探索更多 GitHub 内容
![]()
Docs
掌握 GitHub 所需的一切内容,集中于一处。
![]()
GitHub
在 GitHub 构建下一代产品——这是一个让任何人在任何地方都能创造任何事物的平台。
![]()
Customer stories
了解那些使用 GitHub 构建产品的公司与工程团队。
![]()
The GitHub Podcast
关注 GitHub Podcast。这档节目聚焦 GitHub 开源开发者社区相关的话题、趋势、故事与文化。

