Together AI 推出 CPD 架构,长上下文推理提速 40%
深度2026年3月4日6 分钟阅读
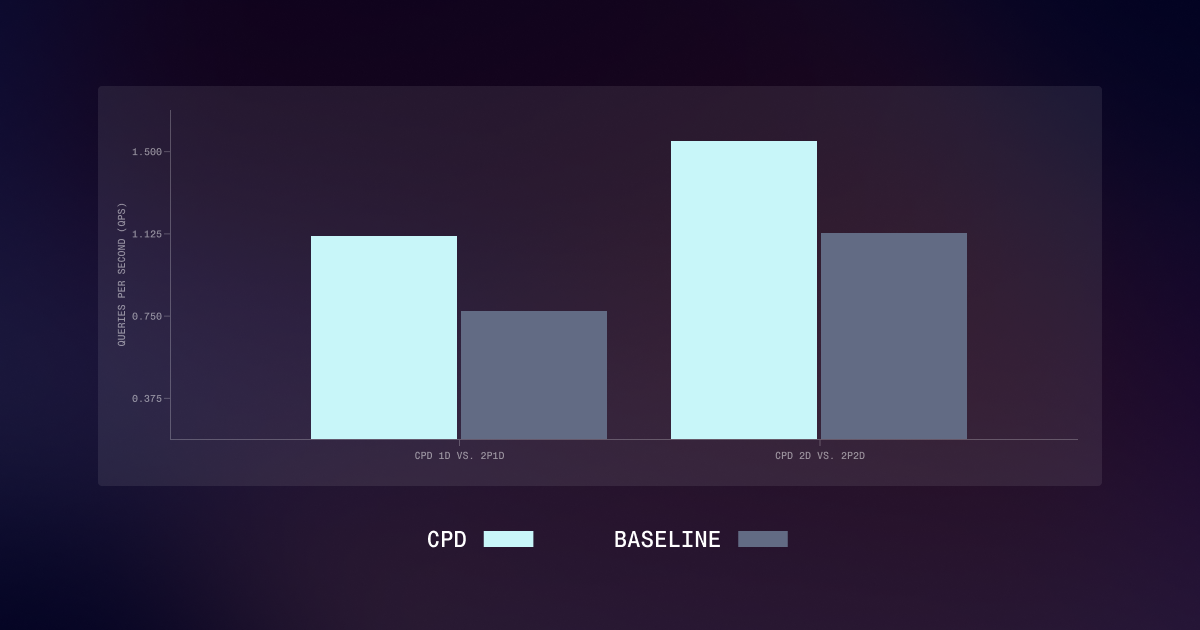
长提示词推理不必再忍受缓慢的响应。Together AI 提出了一种缓存感知的预填充-解码解耦(CPD)架构,通过分离冷热推理工作负载,将长上下文大语言模型推理的吞吐量提升了 40%,并显著降低了首词元延迟。
本文编译自 Cache-aware prefill–decode disaggregation (CPD) for up to 40% faster long-context LLM serving,版权归原作者所有。
觉得有用?分享给更多人