Together AI 实现开源模型推理速度翻倍
指南2025年12月1日4 分钟阅读
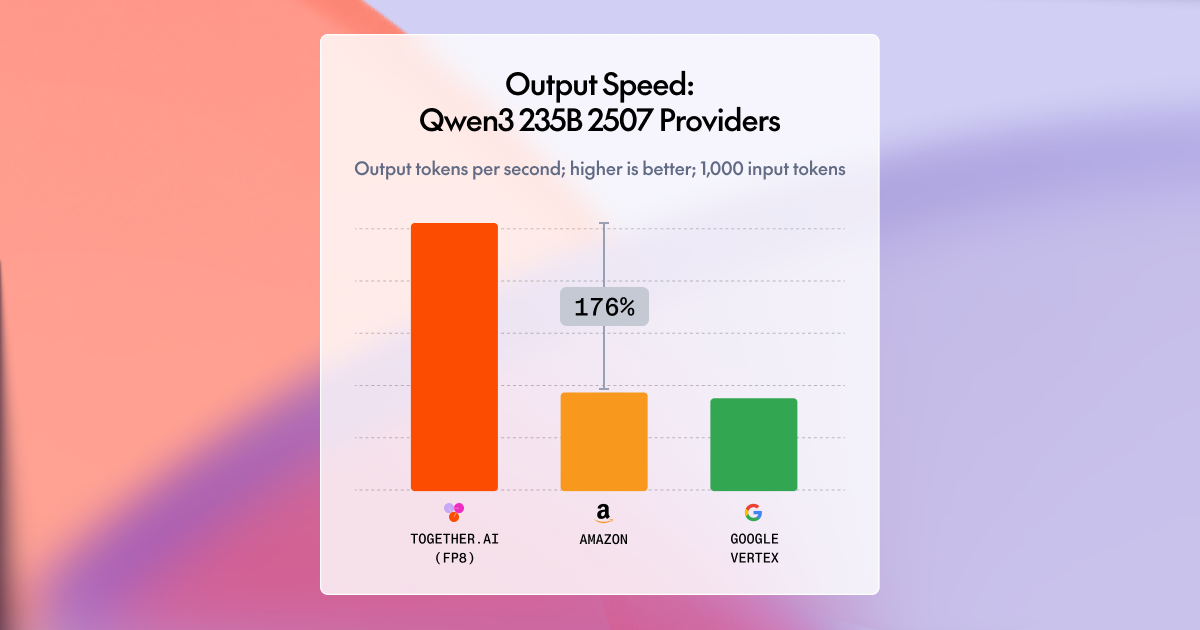
Together AI 通过 GPU 优化、高级推测解码和 FP4 量化,将 Qwen、DeepSeek、Kimi 等主流开源模型的推理速度提升高达 2 倍,在 NVIDIA Blackwell 架构的速度基准测试中排名第一。
觉得有用?分享给更多人
觉得有用?分享给更多人
本文分析了传统 CI/CD 对 LLM 管线的不足,并介绍了基线评估、漂移检测、影子验证和成本延迟检查四个发布关卡。通过实际代码示例,展示了如何将这些关卡集成到现有 CI/CD 流水线中,以在部署前捕捉模型漂移和回归。
本文介绍了 digiKam 的自然语言搜索项目设计:通过本地 LLM 将用户输入的口语句子翻译成系统已有的结构化查询条件,再由 digiKam 的搜索引擎执行。文章详细解释了管道流程、选择本地模型的原因、模型下载集成方案以及为何选用 Qwen2.5-1.5B-Instruct 等。