Llama-3-70B 分治策略击败 GPT-4o 长文本处理
深度2026年3月26日4 分钟阅读
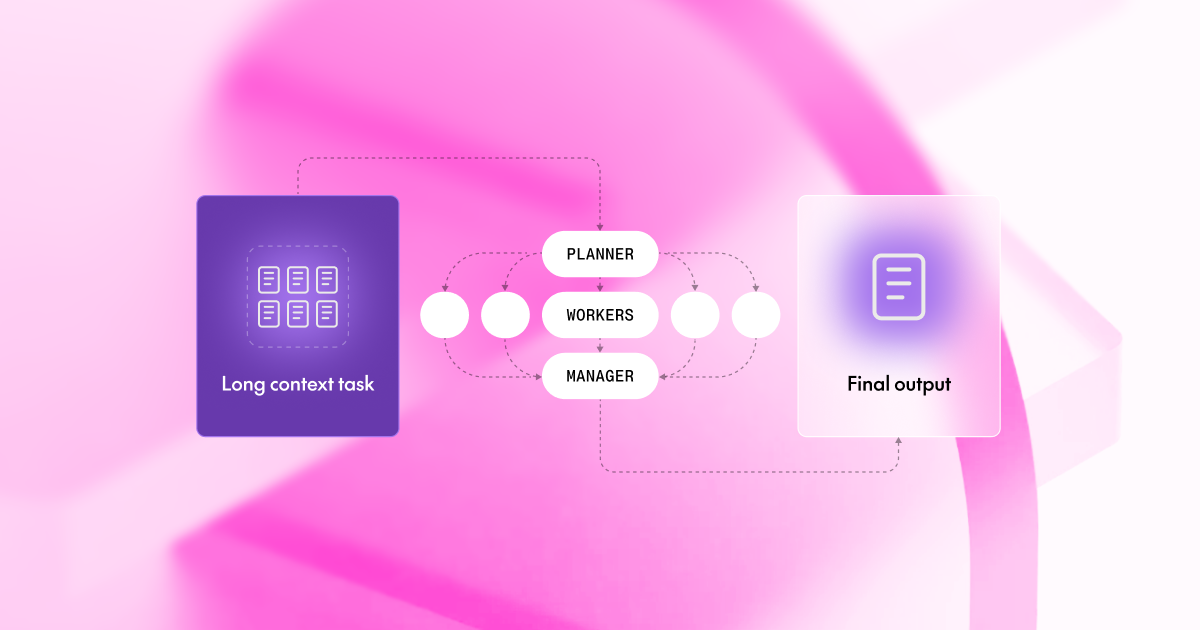
大语言模型(LLM)的上下文窗口(Context Window)越来越大,但性能却会随着文本长度增加而意外下降。研究发现,采用分治(Divide & Conquer)框架——将长文档拆分成并行处理的块,由规划器(Planner)、工作器(Worker)和管理器(Manager)协同——可以让 Llama-3-70B、Qwen-72B 等小模型在长上下文任务上超越 GPT-4o 的单次处理(Single-shot)。
觉得有用?分享给更多人