MoAA:用开源模型集体智慧提升微调效果
深度2025年5月28日5 分钟阅读
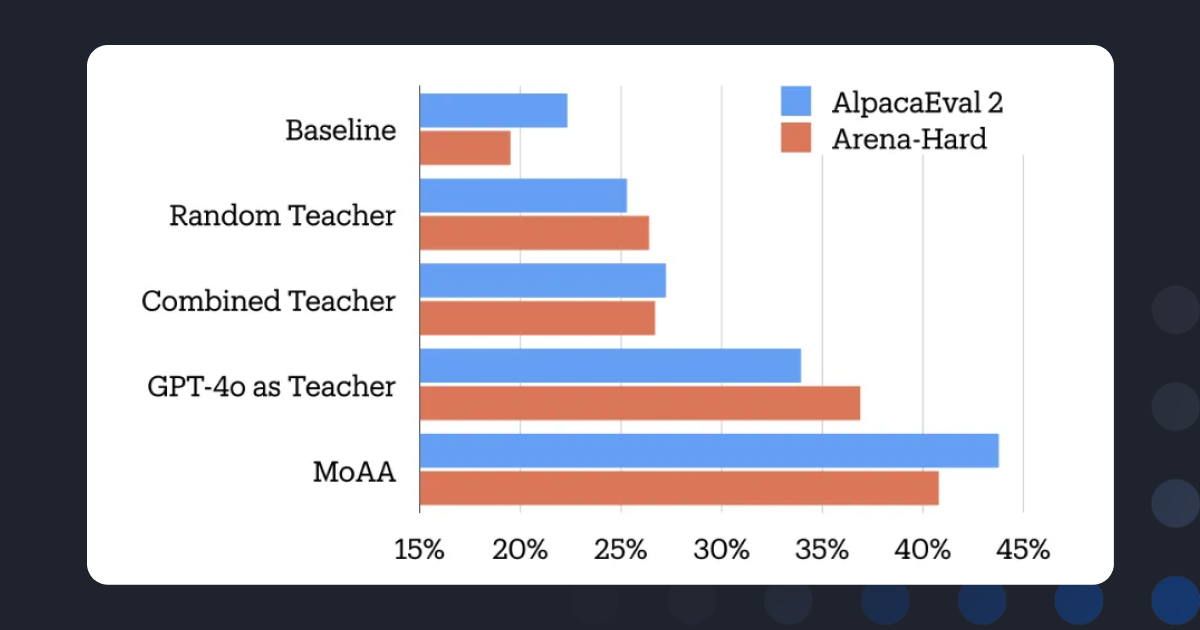
用智能体混合(Mixture-of-Agents)作为教师进行蒸馏微调,效果超过了 GPT-4o。基于 Llama-3.1-8B-Instruct 的模型在 AlpacaEval 2 和 Arena-Hard 上表现优异。
本文编译自 Mixture-of-Agents Alignment: Harnessing the Collective Intelligence of Open-Source LLMs to Improve Post-Training,版权归原作者所有。
觉得有用?分享给更多人