执行框架工程让智能体从 Top 30 冲到 Top 5
深度LangChain2026年2月17日7 分钟阅读
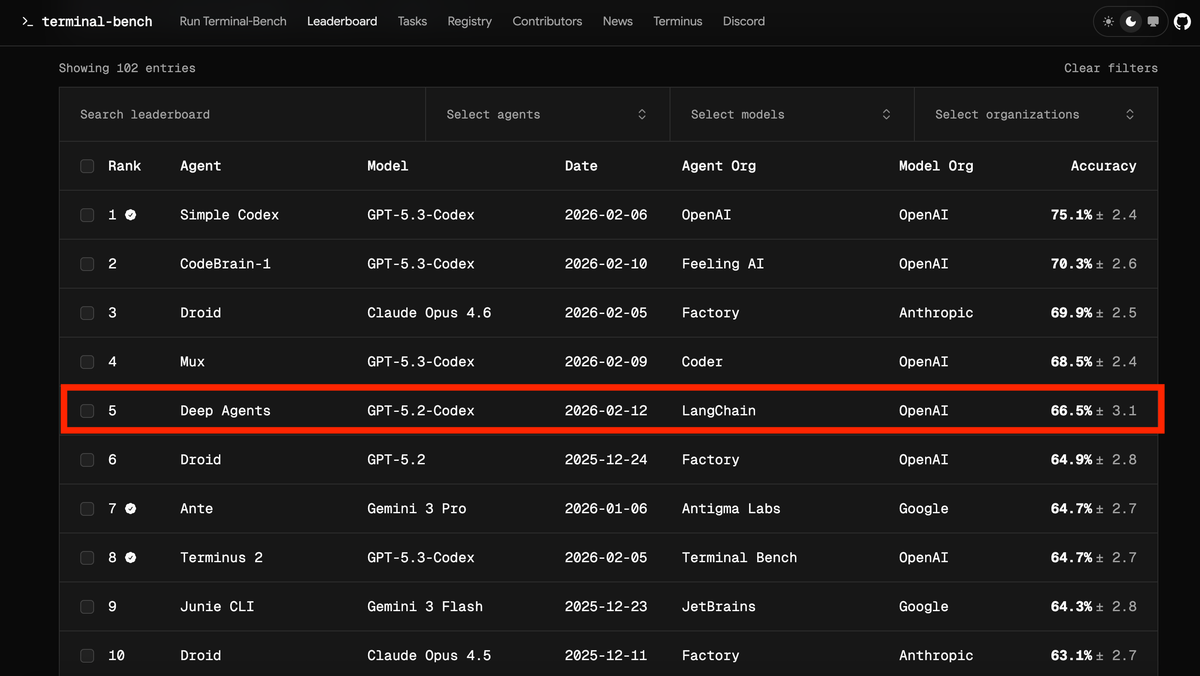
LangChain 团队仅通过优化执行框架(Harness),就让其编码智能体在 Terminal Bench 2.0 上的得分从 52.8 提升至 66.5,排名从 Top 30 外跃升至 Top 5。他们分享了基于追踪分析和自验证等关键方法的执行框架工程实践。
本文编译自 Improving Deep Agents with harness engineering,版权归原作者所有。
觉得有用?分享给更多人