代码评审已死,人类应专注上游决策
深度Latent Space2026年3月2日5 分钟阅读
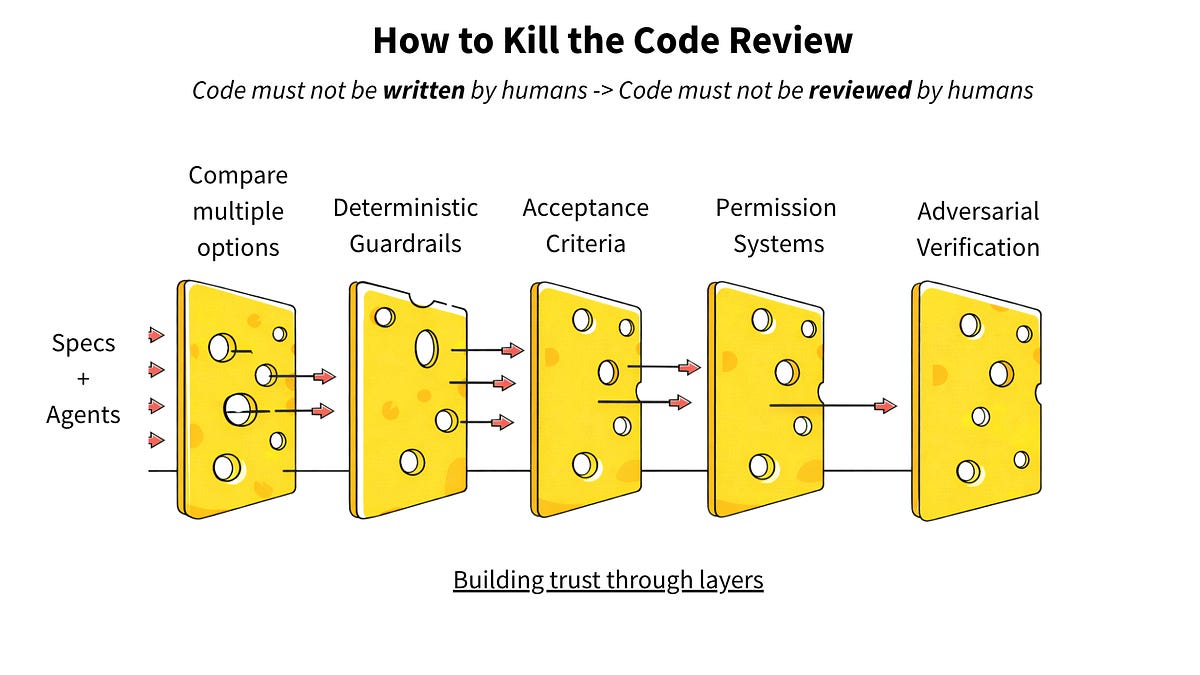
AI 让代码产出量激增,手动代码评审已无法跟上节奏。数据显示,高 AI 采用率的团队 PR 评审时间增加了 91%。解决方案是将人工检查点前移,让人类专注于评审规范、约束和验收标准,而非逐行审查代码。
本文编译自 How to Kill the Code Review,版权归原作者所有。
觉得有用?分享给更多人
觉得有用?分享给更多人
Black Forest Labs 推出 FLUX 3,统一多模态模型,视频生成超越多个竞品,并开源 FLUX-mimic 用于机器人控制。同时,The Stack v3 数据集发布,蒸馏政策争议持续。
本文采访了多位进攻型网络安全研究员,探讨AI公司的安全护栏如何影响他们发现漏洞和开发利用工具的工作。研究员们普遍认为护栏过于严格且不一致,迫使部分人转向国产开源模型。