拆解智能体:编码助手的六大组件
深度2026年4月5日6 分钟阅读
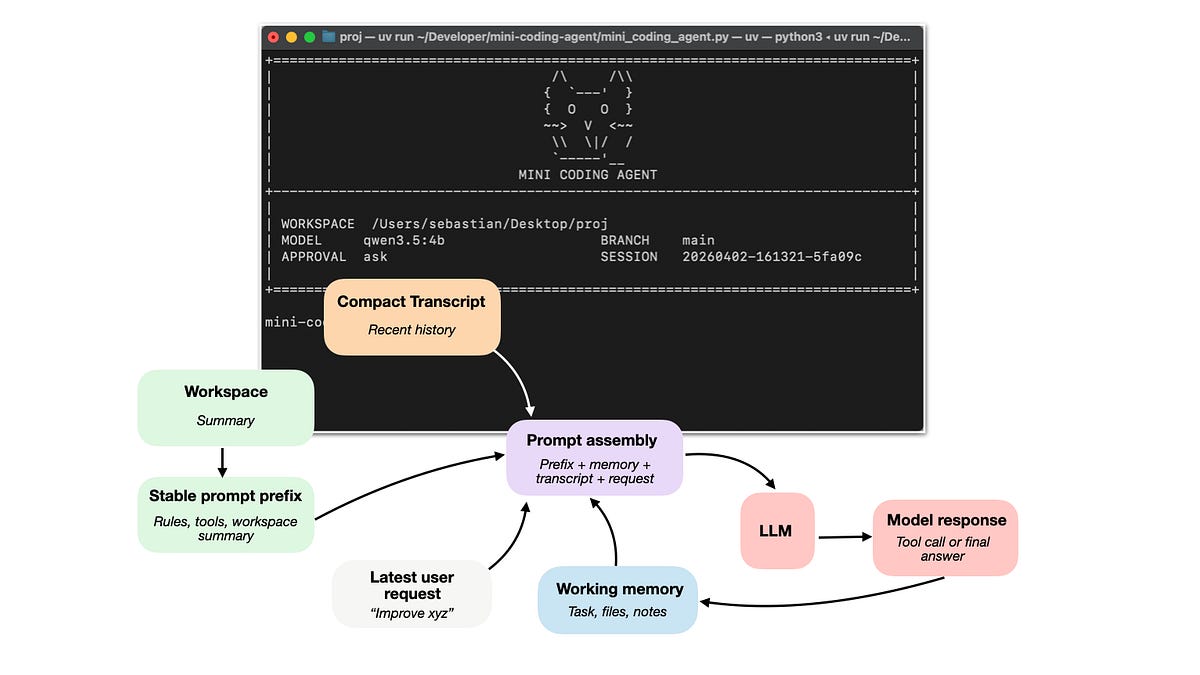
为什么 Claude Code 和 Codex 比直接用大语言模型聊天更强大?关键在于它们背后的智能体执行框架(Harness)。本文作者 Sebastian Raschka 拆解了编码智能体的六大核心组件,并开源了一个纯 Python 实现的 Mini Coding Agent 作为示例。
本文编译自 Components of A Coding Agent,版权归原作者所有。
觉得有用?分享给更多人
觉得有用?分享给更多人
新版 Claude 模型在调用 Pi 的 edit 工具时,会在嵌套的 edits 数组中凭空捏造大量额外键(如 requireUnique、oldText2 等),导致工具调用失败。作者分析认为,这是由于模型在后训练中过度适应了 Claude Code 的扁平编辑工具 schema,遇到不同形状的工具时更易生成不符合 schema 的调用。开启 strict 模式可解决,但显示了后训练对模型行为的深刻影响。
阿里巴巴报告将禁止员工使用 Anthropic 的 Claude Code 编程工具,自7月10日起生效。该工具被列为高风险软件,员工将被要求使用阿里自研的 Qoder 替代。此前 Anthropic 已禁止中国公司使用其模型,并曾通过实验性代码识别中国用户以防止滥用。