Ask a Techspert:AI 如何理解我的视觉搜索?
Your browser does not support the audio element.
收听文章
本内容由 Google AI 生成。生成式 AI 仍处于实验阶段
[[duration]] 分钟
我们都有过这样的时刻:看到一张布置得恰到好处的客厅照片,或是一套搭配完整的街拍造型,就想知道里面每一件东西都来自哪里。直到不久前,视觉搜索还是“一次只搜一个”的模式。但 Circle to Search 和 Lens 的一次重大更新,如今让 Google 可以在单张图片中同时拆解并搜索多个对象。这意味着,如果你在 Android 上用 Circle to Search 搜索整套穿搭,你会看到整套造型中每个单品的结果,而不只是一次一个。过去几个月里,我们也在 AI Mode 中推出了多项更新,进一步增强视觉搜索和图片结果,帮助你在搜索时更高效地找到灵感。
为了更好地理解这些突破,我们采访了 Search 高级工程总监 Dounia Berrada。
你在 Search 里负责哪一部分?
我主要负责多模态搜索,也就是 Google Lens——本质上,是让 Google 能帮助你处理关于图片、PDF,以及你所见万物的复杂问题。视觉搜索正在重塑我们与信息交互的方式;Lens 应该足够智能,能理解你搜索背后的“为什么”,让你无论是在屏幕上看到的内容,还是现实世界里看到的东西,都能轻松获得帮助。这意味着我们要打造的工具,既能解释复杂的数学题,也能识别稀有多肉植物,或帮你找到一双你很喜欢的鞋。
它是怎么做到的?
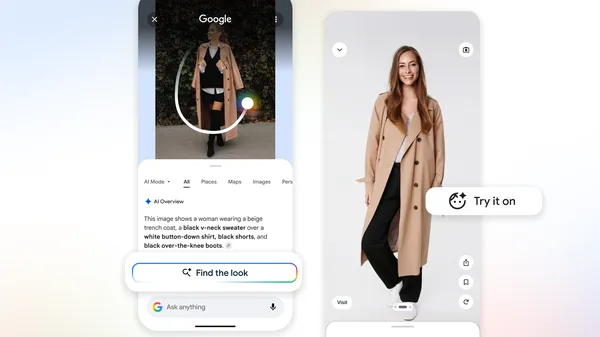
想象你正在重新设计房间,于是上传一张中世纪现代风格空间的照片作为灵感。你很可能不只是想找边桌,而是想复刻整个氛围。以前,你得分别搜索台灯、地毯和椅子。现在,AI Mode 可以拆解这张复杂图片,识别其中每个单独元素,并同时发起多次视觉搜索。你现在就可以通过 Circle to Search 看到这个效果。
这类视觉搜索回答背后由什么驱动?
先进的 Gemini 模型让 AI Mode 成为可能,而它的多模态能力也受益于我们多年来在 Lens 中积累的视觉理解能力。当你用图片搜索时,Gemini 会把图片和你的问题一起分析,决定该调用哪些工具。比如,你在手机上刷社交媒体时看到一套很喜欢的穿搭。你发起搜索后,模型会知道调用 Lens,同时检索这套造型中帽子、鞋子和夹克的图片结果。然后,它会把这些单独结果编织成一条清晰易读的回答。
你可以这样理解:AI 模型像是能“看见”图片的“大脑”,而视觉搜索后端像是包含海量网页结果的“图书馆”。AI 会进行多对象推理,理解你正在看什么。接着,它使用一种“fan-out”技术,一次触发多个搜索,读取结果并整合成一条连贯回答,附上有用链接——整个过程只需几秒。
你能解释一下 fan-out 技术吗?
AI Mode 基本上是在完成一次搜索的时间里,替你做了十几次搜索。比如你上传一张喜欢的花园照片,你可能会有好几个问题:这些植物能在阴凉处存活吗?适合我所在的气候吗?它们需要多少维护?
以前,你得一个个问。现在,AI Mode 会识别这些必要的“fan-out”搜索。这样,它就能借助实用的网页结果,汇总照片中每种植物的养护需求,拆解信息,甚至给出你下一步可能想做的建议。由于 AI Mode 能从一次搜索中挖掘更多视觉结果,你不仅更容易找到自己想要的内容,也更容易偶然发现激发兴趣的新东西。
要获得 AI Mode 这种帮助,一定要先上传图片吗?
完全不用!你可以在 AI Mode 里先进行简单的文本搜索,比如“职场穿搭视觉灵感(visual inspo for work outfits)”。当你看到喜欢的结果后,只要继续说:“给我更多像第二条裙子那样的选择。”系统会立即基于那张特定图片启动 fan-out 流程。
这看起来确实很适合购物——还能用在什么场景?
你可以拍一面博物馆展墙,然后让它解释每一幅画。或者拍一家面包店的橱窗,问里面各种糕点都是什么。关键在于,从“这一个东西是什么?”转向“请给我解释整个场景”。
听起来我得多拍点照片,去发现更多东西了。我要去试试这些工具!
在收件箱中获取更多 Google 故事。
完成。还差最后一步。
请检查收件箱并确认订阅。
你已经订阅了我们的新闻通讯。
你也可以通过以下方式订阅