AI 编程智能体开始「闭环」
深度Latent Space2026年2月25日6 分钟阅读
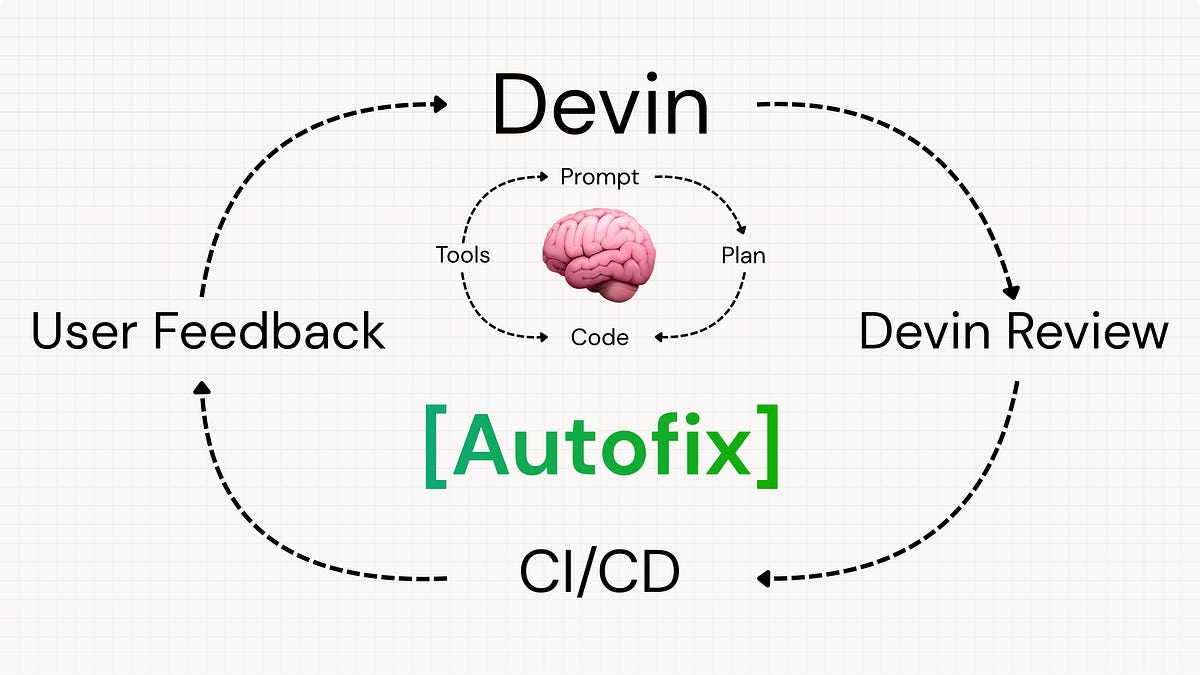
近期多家主流编程智能体公司不约而同地朝「闭合外循环」方向迈进。Cursor 推出视频演示功能,Claude Code 发布远程控制,Cognition 的 Devin 也实现了自动闭环。
本文编译自 [AINews] The Unreasonable Effectiveness of Closing the Loop,版权归原作者所有。
觉得有用?分享给更多人
觉得有用?分享给更多人
OpenAI 和 Anthropic 在同一天发布了语音功能更新。OpenAI 的 GPT-Live 让 ChatGPT 可以通过语音控制桌面应用、多任务并行处理;Anthropic 则强化了 Claude 的语音模式,支持更长的迭代对话和代码讨论。两家公司分别从任务自动化和深度思考两个方向拓展语音交互的边界。
Anthropic 升级 Claude 语音模式,支持 Opus、Sonnet、Haiku 三种模型,并可调用外部应用完成实际任务,如改会议、写邮件。同时新增多语言支持,但免费用户仅限 Haiku 模型和单个连接应用。