GPT-5.4 统一模型发布,原生支持计算机操作
深度Latent Space2026年3月6日4 分钟阅读
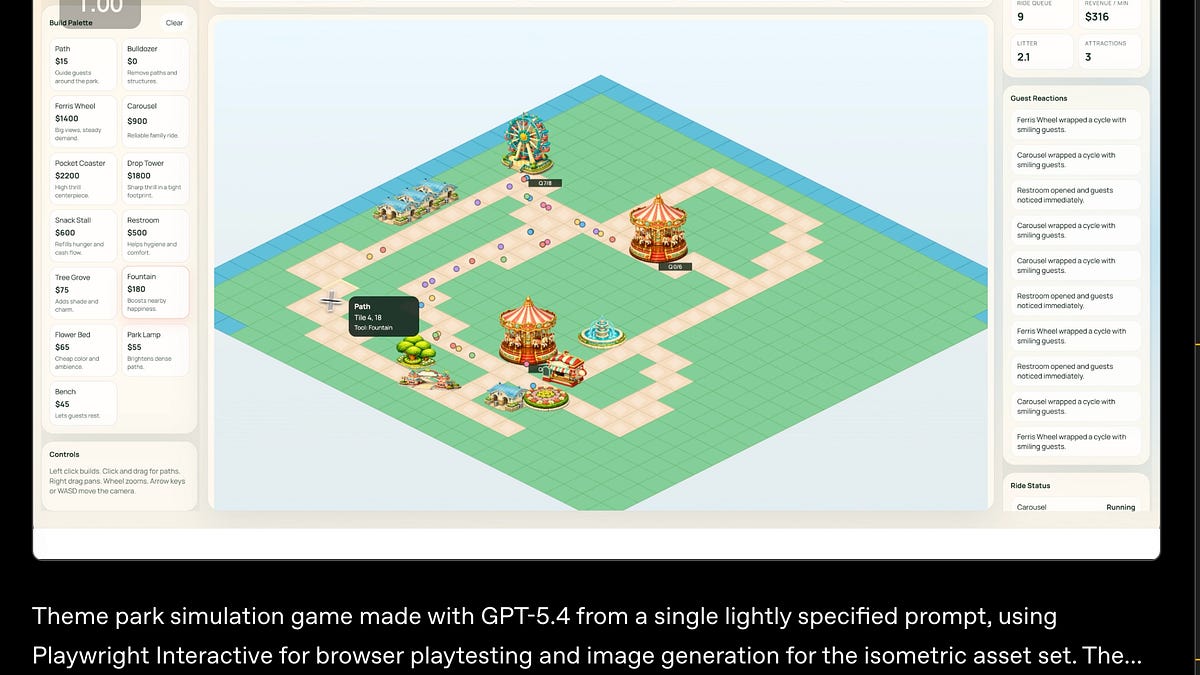
OpenAI 发布了首个统一编程与非编程能力的 GPT-5.4 模型,原生支持计算机操作(CUA),在多项基准测试中超越人类专家。同时,FlashAttention-4 等底层优化技术也取得重要进展。
本文编译自 [AINews] GPT 5.4: SOTA Knowledge Work -and- Coding -and- CUA Model, OpenAI is so very back,版权归原作者所有。
觉得有用?分享给更多人