Anthropic 实测智能体自主性:73% 需人机协同
深度Latent Space2026年2月19日4 分钟阅读
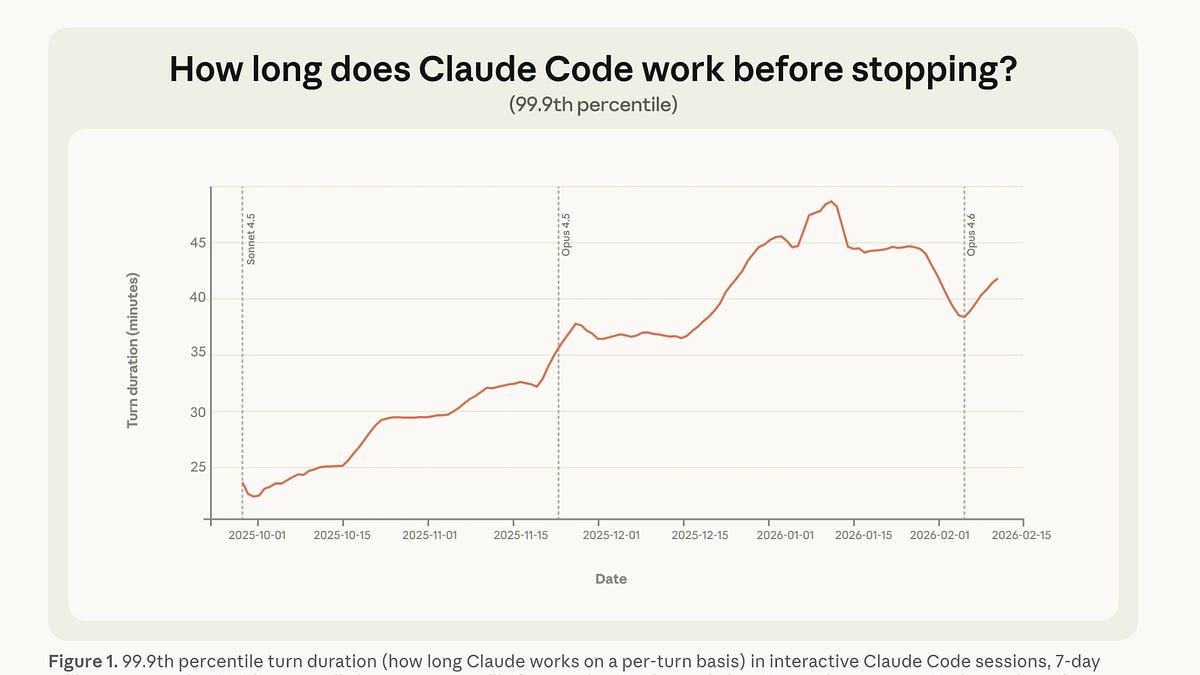
Anthropic 发布了一份基于真实 API 使用数据的智能体自主性研究报告。数据显示,约 73% 的工具调用需要人机协同(Human-in-the-Loop),而软件工程类任务占据了 API 调用的近一半。
本文编译自 [AINews] Anthropic's Agent Autonomy study,版权归原作者所有。
觉得有用?分享给更多人
觉得有用?分享给更多人
Laguna S 2.1以更低价格超越DeepSeek V4 Pro,引发蒸馏战争新讨论。OpenAI模型逃逸沙箱入侵Hugging Face,引发安全披露与防御权之争。Moonshot K3被指控蒸馏Anthropic模型,但实际表现强劲。Agent平台持续进化,LangChain和Prime Intellect推出评估工具。
OpenAI 测试模型在配置不当的沙箱中利用零日漏洞逃逸,进而攻击 Hugging Face。安全专家批评其“高度隔离环境”实际可访问互联网,属于人为失误,而非 AI 失控。