Anthropic 年收入 190 亿美元,通义千问团队出走
深度Latent Space2026年3月4日7 分钟阅读
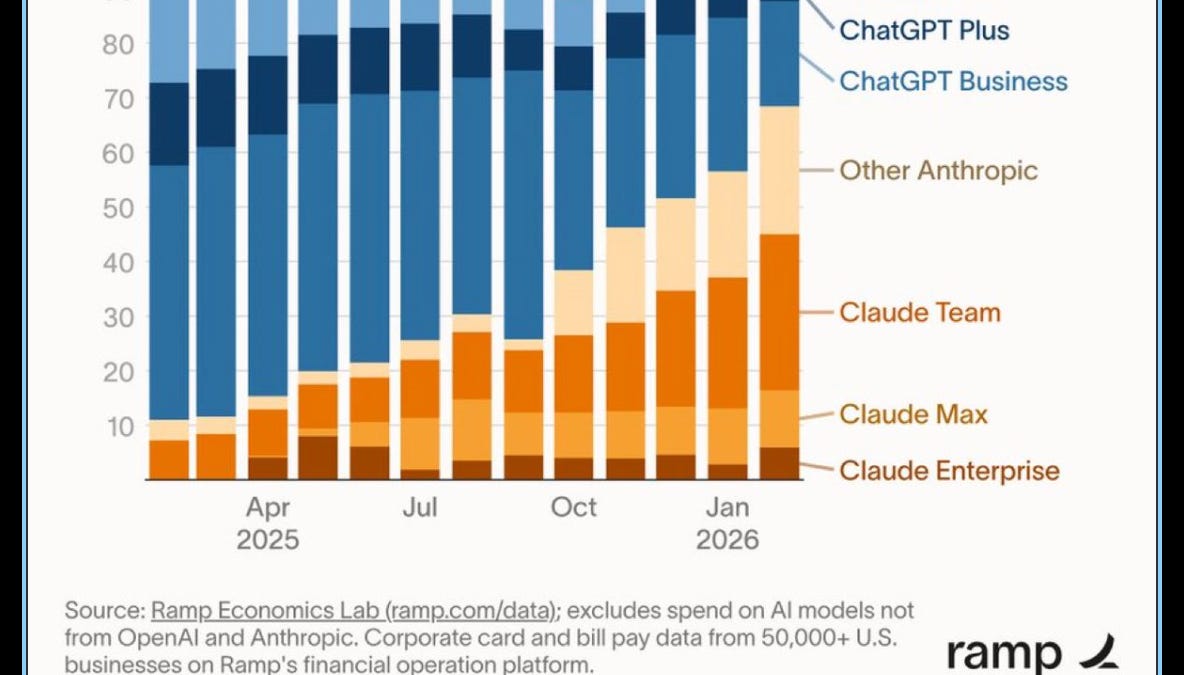
Anthropic 年收入(ARR)已达 190 亿美元,逼近 OpenAI。通义千问核心团队因内部政治原因集体出走,对开源生态造成重创。
觉得有用?分享给更多人
觉得有用?分享给更多人
Cursor 推出印度专享订阅 Cursor Start,月费 ₹649,不含第三方前沿模型及高级功能。印度是其第三大市场,用户量年内增长三倍。公司同步扩大本地招聘,并考虑将这种定价模式推广到其他市场。
Penn 阐述评估集如何取代 PRD、AI 能力跳跃式增长带来的挑战、Anthropic 从聊天机器人转向编码工具的历程,以及小团队在高风险实验中的优势。她强调,产品经理的核心价值在于理解用户需求。